

In Oracle SQL, data type conversion is changing a value from one data type to another[1]. Data type conversion is often necessary in many scenarios, such as making input values compatible with the column definitions or ensuring column values compatible with a specific operation.
In Oracle SQL, type conversion refers to the process of changing a value from one data type to another. This is often necessary for many operations, such as:
- Performing calculations: When combining numerical values stored as different data types (e.g., NUMBER and VARCHAR2), conversion ensures compatible formats for arithmetic operations.
- Comparing values: Comparisons between different data types (e.g., DATE and VARCHAR2) require conversion to common type for accurate results.
- Storing values: Assigning values to columns with specific data types may necessitate conversion to match the column's definition.
Conversion functions do not change any stored values; rather, they modify the data type for the values. Consider a scenario where financial values are stored as text, including dollar signs and other symbols that a mathematical function may reject, triggering an error message.

In such cases, a conversion function can be employed to transform the text value into a numeric data. For example:

Implicit vs Explicit Conversion
In Oracle SQL, implicit conversion refers to the automatic data type change from one data type to another without explicit instructions from the user. It occurs automatically in circumstances when operands for an operation have different data types, Oracle tries implicit type conversion to make them compatible. For example, in the figure shown below, Oracle implicitly converted a text string ('3') into a numeric value in order to perform addition:

Oracle has a certain order of precedence for implicit type conversions. It basically prioritizes values with higher-precision and more detailed data types, meaning that the value with lower-precision will be matched to another value. Here's an overview of the hierarchy, from highest to lowest priority:
- Datetime and Interval Data Types:
- Dates and timestamps, including intervals representing durations, come first in the hierarchy.
- BINARY_DOUBLE and BINARY_FLOAT:
- These floating-point data types with high precision can represent a wider range of decimal values.
- NUMBER:
- Numeric data type encompassing integers, decimals, and floating-point values with moderate precision.
- Character Data Types:
- Includes fixed-length (CHAR, NCHAR) and variable-length (VARCHAR2, NVARCHAR2) character strings.
- All Other Built-in Data Types:
- Less commonly used types like ROWID or cursors fall last in the hierarchy.
Note: Oracle's documentation cautions that the behavior of implicit conversion is subject to change across software releases.
When applying operations on values with different data types, Oracle automatically converts the lower-priority type to align with the higher-priority one. This automatic conversion can result in unexpected outcomes if you're not aware of the hierarchy. For example, comparing a string ('10') to a number (5) will lead to the implicit conversion to a number (10) before the comparison. If this is your intension, it might be okay. If unintended, an implicit type conversion can introduce logical errors. However, it is considered good design to minimize reliance on automatic data type conversion and explicitly articulate your intentions in the code. This practice ensures that your code's intent is clearly documented and remains supported in the future.
The CAST Function
Using CAST function is one simple way to perform an explicit data type conversion. This can be useful when you need to ensure compatibility between different data types in SQL queries or when you want to display data in a specific format.
The basic syntax of the CAST function is as follows:
CAST(expression AS data_type);
Where expression is the value or column that you want to convert, and data_type is the target data type to which you want to convert the expression. For example, let's say you have a column named 'price' with data type NUMBER and you want to convert it to VARCHAR2 for display purposes. You can use the CAST function as below:

In this example, the 'price' column is cast to VARCHAR2 with a maximum length of 10 characters. You can adjust the target data type and length based on your specific requirements.
It is important to note that the CAST function is similar to the TO_CHAR, TO_DATE, and TO_NUMBER function in Oracle SQL, but it provides a more ANSI SQL-compliant way of performing data type conversions.
Implicit vs. Explicit Type Conversion
Type conversions can either be implicit or explicit. Explicit conversion occurs when type conversion is initiated through explicit function calls, such as TO_NUMBER or TO_CHAR. On the other hand, implicit conversion refers to the automatic type change of values without any explicit instructions from SQL commands.

Oracle performs implicit conversions when necessary to facilitate operations, based on its conversion precedence. For example:

Because the operands for the operation had different data types, Oracle attempted implicit type conversion to make '3' compatible for addition.
Oracle has a certain order of precedence for implicit type conversions. It basically matches values with lower-precision and shorter data types to the values with higher-precision and longer data types. Here's an overview of the precedence order for the implicit type conversion, from highest (1) to lowest (5):
- Datetime and Interval Data Types: Dates and timestamps, including intervals representing durations, come first in the hierarchy.
- BINARY_DOUBLE and BINARY_FLOAT: These floating-point data types with high precision can represent a wider range of decimal values.
- NUMBER: Numeric data type encompassing integers, decimals, and floating-point values with moderate precision.
- Character Data Types: Includes fixed-length (CHAR, NCHAR) and variable-length (VARCHAR2, NVARCHAR2) character strings.
- All Other Built-in Data Types: Less commonly used types like ROWID or cursors fall last in the hierarchy.
Note: Oracle's documentation cautions that the behavior of implicit conversion is subject to change across software releases.
When applying operations on values with different data types, Oracle automatically converts the lower-priority type to align with the higher-priority one. This automatic conversion can result in unexpected outcomes if you're not aware of the precedence order. For example, adding a string ('3') to a number (20) will lead to the implicit conversion of ('3') before the comparison. If this is your intension, it might be okay. If unintended, an implicit type conversion can introduce logical errors.
While it is good to know for debugging purpose, introducing implicit type conversion is not a good practice; you should always explicitly instruct your intentions in the code. Implicit conversions can sometimes lead to unexpected results. Particularly, Oracle's conversion rules can change in the future versions. This might break your code if it relies on implicit conversions. Besides, implicit conversion forces Oracle to take extra steps to convert data types, which could slow down your queries. Thus, it is generally not recommended on implicit type conversions in practice.
Converting Character Strings
TO_NUMBER('string', 'format_model', 'nls_parms')
TO_NUMBER function converts string literal (string) into NUMBER data type. For example:

Optionally, you can add format_model to instruct how incoming strings are formatted. This parameter is particularly useful when numeric string includes specific units such as financial currencies. For example:

Commonly used number format elements that you can comprise a format_model with are:
| Element | Description | Example |
|---|---|---|
| ,. | Commas and decimal points will pass through wherever they are included. Note that only one period is allowed per format mask. | 9,999,999.99 |
| $ | Leading dollar sign. | $9,999,999.99 |
| 0 | Leading or trailing zero. | 0099.99 |
| 9 | Any digits. | 999 |
| B | Leading blank for integers. | B999 |
| C | ISO currency symbol as defined in the NLS_ISO_CURRENCY parameter. | C9,999.99 |
| D | Current decimal character as defined by the NLS_NUMERIC_CHARCTERS parameter. | 999D99 |
| EEE | Value in the scientific notation. | 9.9EEE |
| G | Group separator as defined in the NLS_NUMERIC_CHARACTER parameter. | 9G999 |
| L | Local currency symbol | L999 |
| MI | Trailing minus sign for negative values; trailing blank for positive values. | 999MI |
| PR | Negative values in angle brackets. | 999PR |
| S (prefix) | Negative values with leading minus sign, positive values with leading plus sign. Note that it cannot be used with suffix S. | S999 |
| S (suffix) | Negative values with trailing minus sign, positive values with trailing plus sign. Note that it cannot be used with prefix S. | Row 14, Col 3 |
| TM | Text minimum | TM |
| U | Euro currency symbol or whichever specified by NLS_DUAL_CURRENCY parameter. | U9,999.99 |
| V | Values multiplied by 10n, where n is the number of 9s after the V. | 999V99 |
| X | Hexadecimals. | XXXX |
Optional third parameter serves to specify NLS (National Language Support) settings for the conversion. It allows you to identify any of the three NLS parameter defined in the table below. If included, the third parameter consists of a single string that encompasses any one or more of these NLS parameters for the 'nls_parms' specification:
| Element | Description |
|---|---|
| NLS_NUMERIC_CHARACTERS = 'dg' | d is the decimal character specification, while g is the group separator. |
| NLS_CURRENCY = 'text' | Where 'text' is your specification for local currency symbol. |
| NLS_ISO_CURRENCY = 'currency' | Where 'currency' is the international currency symbol that you want to specify. |
For example:

Note that all three arguments for the function must be enclosed by single quotation marks. Duplicated single quotation marks around ',.' were used for escaping.
To Datetime and Intervals
TO_DATE('string', 'format_model', 'nls_parms')
To convert a character string ('string') into a datetime value, you should use the TO_DATE function. This function is commonly used for converting non-standard date representations stored as a character string into the system's default date format. Or when you expect entering values have varying date formats that are different from the system settings.
Similar to TO_NUMBER function, the TO_DATE function has two optional parameters: 'format_model' instructs how the string is formatted, and 'nls_parms' specifies the NLS parameters for the conversion. For example:

Table below summarizes the date format elements:
| Element | Description | Element | Description |
|---|---|---|---|
| AD/A.D. BC/B.C. | Anno Domini or Before Christ indicator, with or without periods. | AM/A.M. PM/P.M. | Morning or afternoon hours, with or without periods. |
| CC/SCC | Century. | D | Day of the week, 1 through 7. |
| DAY | The name of the day spelled out. | DD | Day of the month, 1 through 31. |
| DDD | Day of the year, 1 through 366. | DL | Long date format. Appearance determined by NLS_TERRITORY and NLS_LANGUAGE, e.g., sample AMERICAN_AMERICA output is 'Saturday, November 23, 1991.' |
| DS | Short date format. Appearance determined by NLS_TERRITORY and NLS_LANGUAGE, e.g., sample AMERICAN_AMERICA output is '11/23/1991.' | DY | Abbreviated name of day, e.g., SUN, MON, TUE, etc. |
| E | Abbreviated era name. | EE | Full era name. |
| FF | Fractional seconds. | FM | Used in combination with other elements to direct the suppression of leading or trailing blanks. |
| FX | Exact matching between the character data and the format model. | IW | Week of the year, 1 through 53. |
| I IY IYY | Last one, two, or three digits of the ISO year[7]. | J | Julian day, counted as the number of days since January 1, 4712 B.C. |
| MON | Abbreviated name of month, e.g., JAN, FEB, MAR, etc. | MONTH | Name of month spelled out. |
| PR | If negative, numbers are enclosed with angle brackets (<>). If positive, returned with leading and trailing spaces. PR follows specification, e.g., 9999PR. | RM | Roman numeral month. |
| RR | Two digit years, where 00 through 49 interpreted as 21st century, 50 through 99 interpreted as 20th century. | RRRR | Four digit years. If only two digits are provided, it will be interpreted as RR. |
| Q | Quarter of year. | WW | Week of the year, 1 through 53. Week 1 starts on the 1st day of the year and ends on the 7th day of the year. |
| W | Week of the month, 1 through 5. Week 1 starts on the 1st day of the month and ends on the 7th day of the month. | X | Local radix character. This is the character used in a numeric representation to separate an integer from its fractional part. |
| Y,YYY | Year with comma in position. | YEAR SYEAR | The year spelled out in English. The S version causes BC dates to display with a minus sign prefix. |
| YYYY SYYYY | Four-digit year. The S version causes BC dates to display with a minus sign prefix | YYY YY Y | The last three digits, two digits, or one digits of the year. |
| - / , . ; : | Punctuation that is accepted in place and passed through as is. | "text" | Literal value. Display as is. |
For example:

TO_TIMESTAMP('string', 'format_model', 'nls_parms')
TO_TIMESTAMP converts the given character string ('string') into a valid TIMESTAMP value. It has two optional parameters: 'format_model' to instruct how the string is formatted and 'nls_parms' to specify the NLS parameters for the conversion. Along with the format elements for the TO_DATE function we've seen earlier, it has the following elements to format hour, minute, and seconds:
| Element | Description | Element | Description |
|---|---|---|---|
| HH HH12 | Hour of the day, 1 through 12 (both are identical). 12 midnight is represented as 12. | HH24 | Hour of the day, 1 through 24. 12 midnight is represented by 00. |
| MI | Minute, 1 through 59. | SS | Seconds 0 through 59. |
| SSSS | Seconds past midnight, 0 through 86399. | FF | Fractional seconds. |
For example:

TO_TIMESTAMP_TZ('string', 'format_model', 'nls_parms')
TO_TIMESTAMP_TZ converts the character string ('string') into a value of TIMESTAMP WITH TIME ZONE, where 'string' must be in the TIMESTAMP format. Optional parameter, 'format_model', defines the format in which 'string' stores the TIMESTAMP WITH TIME ZONE information. 'nls_parms' is the same parameters we've seen earlier with TO_NUMBER function. The time zone defaults to that defined by the SESSION parameter. For example:

Note: there isn't a specific function designed to convert values into the TIMESTAMP WITH LOCAL TIME ZONE. For the purpose, use CASE, described later in this guide.
TO_YMINTERVAL('y-m') and TO_DSINTERVAL('timestamp', 'nls_parms')
TO_YMINTERVAL converts a string value of 'y-m' into an INTERVAL YEAR TO MONTHS, where y represents year and m represents month. For example:
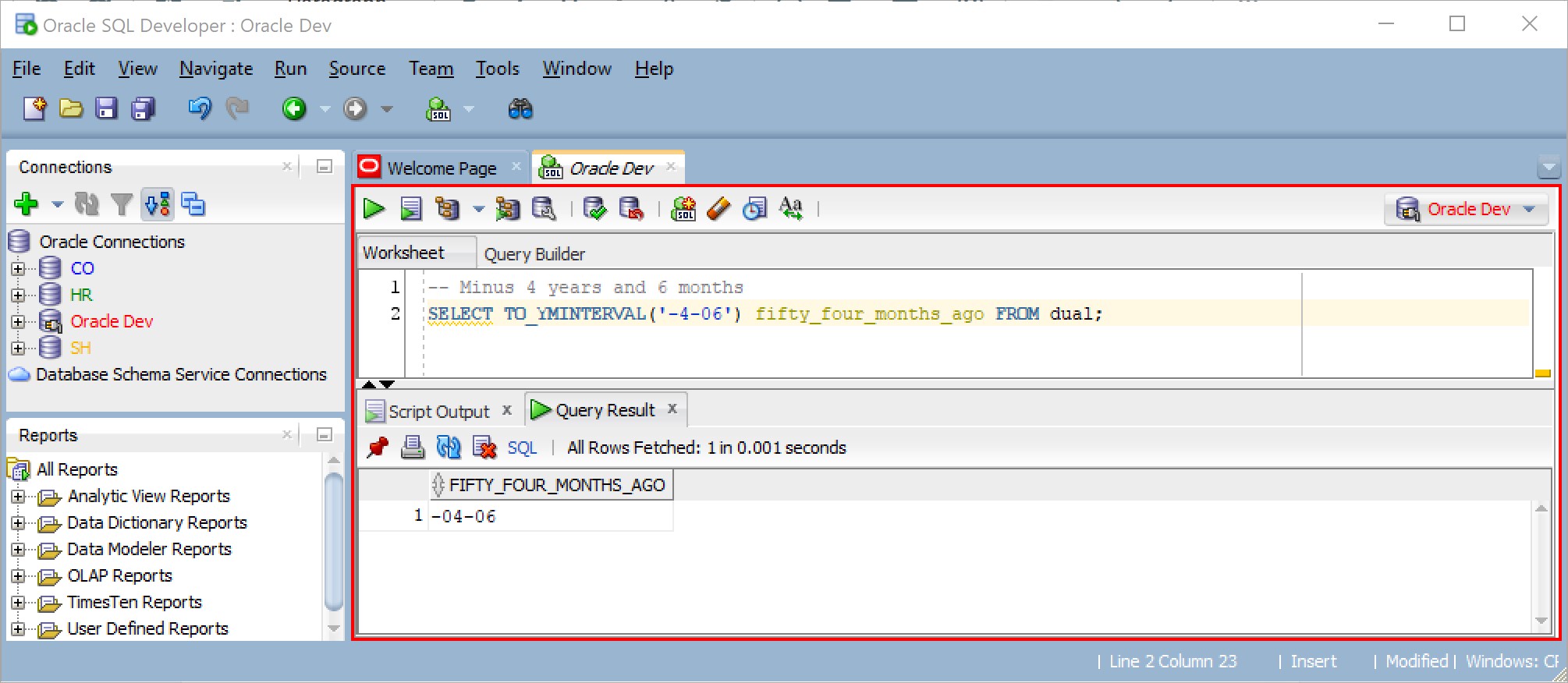
Similarly, TO_DSINTERVAL converts a string value of 'timestamp' into an INTERVAL DAY TO SECOND, where timestamp is a valid timestamp literal. For example:

Converting Numbers
TO_CHAR (n, 'format_model', 'nls_parms')
When applied to a number n, TO_CHAR converts the number into a character data type based on the formats specified by two optional parameters: 'format_model', which comprises one or more format elements, and the 'nls_parms', which is optional and corresponds to the same parameter used in the TO_NUMBER function.
For example:

To Intervals
NUMTOYMINTERVAL(n, interval_unit)
NUMTOYMINTERVAL converts date information provided by a numeric literal into an interval value of time. For example:

In this example, NUMTOYMINTERVAL takes the number literal of 27 and converts it into a value representing a time interval of 27 months, which equates to 2 years and 3 months, in the INTERVAL YEAR TO MONTH data type. Note that 'interval_unit' must be either 'MONTH' or 'YEAR'.
NUMTODSINTERVAL(n, interval_unit)
Similar to NUMTOYMINTERVAL, NUMTODSINTERVAL converts date information in numeric form into an internal value of time. To be valid, 'interval_unit' must be one of the following: 'DAY', 'HOUR', 'MINUTE', or 'SECOND'. For example:

In this example, NUMTODSINTERVAL takes a number literal of 27 and converts into an INTERVAL DAY TO SECOND. Since 'interval_unit' is set to be 'HOUR,' 27 is transformed into 1 day and 3 hours.
Converting Date
TO_CHAR(d, 'format_model', 'nls_parms')
When applied to a datetime or an interval (d), TO_CHAR converts it into a character string using the specified format ('format_model') and ('nls_parms'). Components for the two parameters are the same as those for TO_DATE, TO_TIMESTAMP, TO_TIMESTAMP_TZ, TO_YMINTERVAL, and TO_DSINTERVAL.
A frequent error in the format model is mistakenly using MM when the intention is to represent minutes. For example:
In the figure shown above, I mistakenly used format model DL HH24:MM:SS. While my intention is to represent the current minute, MM returns the current month (01, January) in the output! The correct format model for the purpose is DL HH24:MI:SS, not MM!
Another common error is the potential confusion between RR and YY. In Oracle SQL, the RR represents the two-digit years from 1950 to 2049, whereas YY is 21st century. For example:
CAST(expression AS data_type)
Using CAST function is one simple way to perform an explicit data type conversion. This can be useful when you need to ensure compatibility between different data types in SQL queries or when you want to display data in a specific format.
Where expression is the value or column that you want to convert, and data_type is the target data type to which you want to convert the expression. For example, let's say you have a column named 'price' with data type NUMBER and you want to convert it to VARCHAR2 for display purposes. You can use the CAST function as below:
In this example, the 'price' column is cast to VARCHAR2 with a maximum length of 10 characters. You can adjust the target data type and length based on your specific requirements.
It is important to note that the CAST function is similar to the TO_CHAR, TO_DATE, and TO_NUMBER function in Oracle SQL, but it provides a more ANSI SQL-compliant way of performing data type conversions.
In Oracle, an interval represents a period of time between two particular dates or date time points. It is a built-in data type used to store and manipulate durations. While you can directly add/subtract date values, I find it easier and clearer to use intervals in some situations. For example, suppose that you want to figure out 5 months ahead from today:
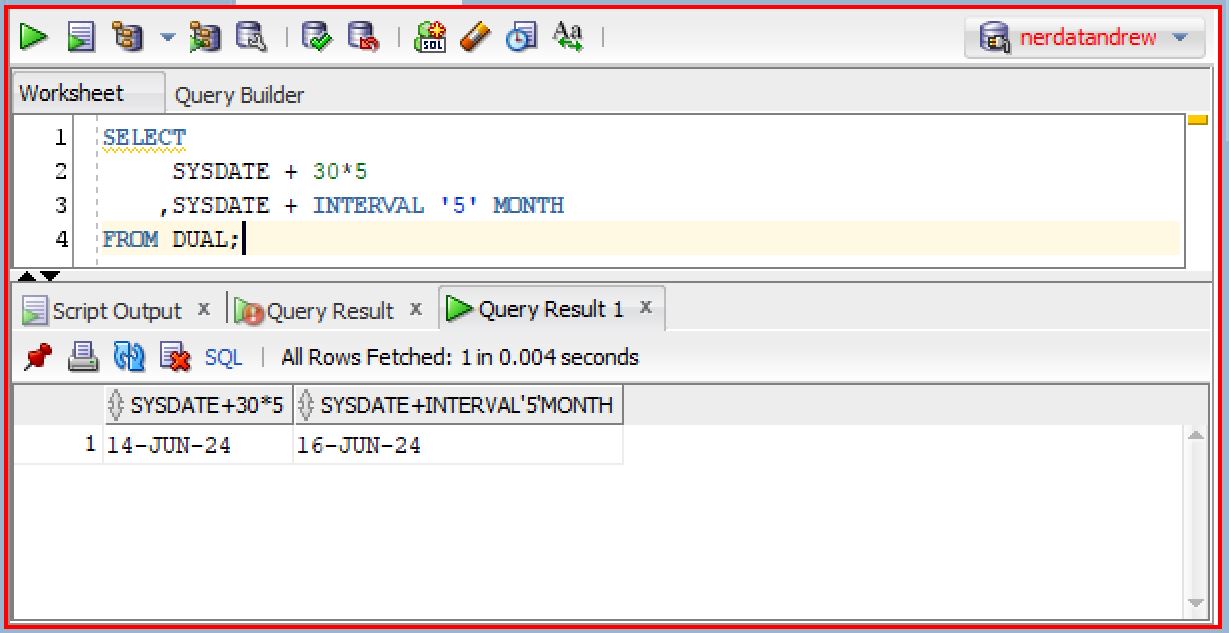
When performing arithmetic operations between dates or datetime values, the default unit is days. To add 5 months from the current day, it is necessary to account for the varying number of days in each month. For example, in the duration between the current day (16-Jan-2024) and 5 months ahead, February has 29 days, March has 30 days, etc. The number of days in February also depends on the year, so that there are 29 days in February 2024, whereas there are 28 days in February 2025. Therefore, specifying the unit of the interval in the operation is advisable to ensure accuracy.
INTERVAL YEAR(n) TO MONTH
One of the interval data type available in the Oracle Database is INTERVAL YEAR TO MONTH. This data type stores a duration defined by year and month values, where n represents the number of digits used for the YEAR value. The acceptable range for n is 0 to 9. This can represent a fairly high amount, nine figures of years (999,999,999 years). If omitted, n defaults to 2. Here is an example:

In the figure shown above, there is a column named my_interval specified interval year range of 3. Thus, the column can take any year intervals ranging from -999 to 999. Then in the line 6, I inserted '123-11' which indicates 123 years and 11 months. When it is represented in the data table, we got plus 123 hyphen 11. This doesn't mean 123 minus 11. Rather it means 123 years and 11 months.
Negative values are applicable to intervals as well. In line 12, I inserted '-23-11'. This represents a duration of minus 23 years and 11 months, equivalent to 287 months ago. Again, the - sign between the two numbers is not a minus sign; the only minus sign is at the beginning. You can also have intervals just expressed in terms of years or months. In line 18, we have 1123 months, which is equivalent to 93 years and 7 months.
INTERVAL DAY(n1) TO SECOND(n2)
Another interval available in Oracle is called INTERVAL DAY TO SECOND. This data type stores a time span defined in days, hours, minutes, and seconds, with precision for both days (n1) and seconds (n2). The valid range for n1 is 0-9, with a default setting of 2, determining the number of digits allowed when specifying the size of DAY component. On the other hand, the value for n2 represents the fractional seconds precision for the SECOND component, with an acceptable range of 0-9 and default value of 6.
You would find the INTERVAL DAY TO SECOND data type useful when there is a need to capture the time difference between two date values. For example:

In line 4, I specified n1 as 3. This means that the acceptable number of days is ranging from -999 to 999 days. In the same code line, I also specified n2 as 6. This means the fractional seconds will have decimal precision up to 0.000001. Then I inserted 5 different values into the table. First value I inserted is '1 2:3:4.567'. This represents 1 day, 2 hours, 3 minutes, 4.567 seconds. In the representation shown in the query result tab, we see that it is represented as +01 02:03:04.567000.
When inserting a value, we're not necessarily have to go all the way to the fractional seconds; we can just go through minutes or hours. For example, in the line 11, I inserted 3 days, 4 hours, and 5 minutes. However, Oracle will store up to the fractional seconds according to the pre-specified n1 and n2 arguments.
Similarly, we can also input values specified in a single unit of day, hour, minutes, or second. For example, in the line 20, I inserted 1123 minutes to the INTERVAL DAY TO SECOND column. Then Oracle will automatically calculate the number of days, hours, and minutes from the input value.
TO_CHAR
The TO_CHAR function converts a date value stored in your database into a character string with a specific format.
The basic syntax of the TO_CHAR function is as follows:
TO_CHAR(d, format_model, nls_params);
For a date or date interval 'd', 'format_model' and 'nls_parms' tailor string formats with the components listed below:
- AD / A.D. / BC / B.C.: Anno Domini or Before Christ indicator, with or without periods.
- AM / A.M. / PM / P.M.: Morning or afternoon hours, with or without periods.
- CC / SCC: Century.
- D: Day of the week, 1 through 7.
- DAY: The name of the day spelled out.
- DD: Day of the month, 1 thorough 31.
- DDD: Day of the year, 1 through 366.
- DL: Long date format. The appearance is determined by the NLS_DATE_LANGUAGE parameter. For example, with NLS_DATE_LANGUAGE = AMERICA for DL format, output would be like "Monday, January 08, 2024."
- DS: Short date format. Appearance is determined by the NLS_DATE_LANGUAGE parameter. For example, with NLS_DATE_LANGUAGE = AMERICA for DS format, output would be like "1/8/2024."
- FF: Fractional seconds.
- FM: Used in combination with other elements to direct the suppression of leading or trailing blanks.
- FX: Exact matching between the character data and the format model.
- HH / HH12: Hour of the day, 1 through 12 (both are identical). 12 midnight is represented as 12.
- HH24: Hour of the day, 1 through 24. 12 midnight is represented by 00.
- IW: Week of the year 1 through 53.
- WW: Week of the year, 1 through 53. Week 1 starts on the first day of the month and ends on the seventh day of the month.
- W: The week of the month, 1 through 5. Week 1 starts on the first day of the month and ends on the seventh day of the month.
- MI: Minute. 0 through 59.
- SS: Seconds, 0 through 59.
- SSSS: Seconds past midnight 0 through 86399.
- MM: Month in double digits, 01 through 12.
- MON: Abbreviated name of month, such as JAN, FEB, MAR.
- MONTH: Name of month spelled out.
- Q: Quarter of year.
- RR: Two-digit year from 1950 to 2049. For example, RR would interpret 22 as 2022 and 78 as 1978.
- RRRR: Four-digit year.
- YY: Two-digit year with no sliding window. For example, YY would interpret 22 as 2022 and 78 as 2078.
- YYYY: Four-digit year.
- TS: The short time format.
A frequent error in the format model is mistakenly using MM when the intention is to represent minutes. For example:

In the figure shown above, I mistakenly used format model DL HH24:MM:SS. While my intention is to represent the current minute, MM returns the current month (01, January) in the output! The correct format model for the purpose is DL HH24:MI:SS, not MM!
Another common error is the potential confusion between RR and YY. In Oracle SQL, the RR represents the two-digit years from 1950 to 2049, whereas YY is 21st century. For example:

TO_DATE(c, format_model, nls_parms)
In Oracle SQL, TO_DATE converts a character string to a date value. The basic syntax for the TO_DATE function is as follows:
TO_DATE(c, format_model, nls_params);
The character string 'c' is the value on which you want to apply type conversion, 'format_model' is an optional parameter, structuring the interpretation of the character string. It identifies the date information according to the listed earlier. Additionally, nls_parms specifies the national language support parameters for your requirements. The TO_DATE function is particularly useful when you want to convert a non-standard date representations stored as a character string to a system default date format. For example:

In practice, to leverage their formatting capabilities, we often nest conversion functions. For example, to determine the weekday of a particular date, you can nest a TO_DATE within a TO_CHAR function as follows:

TO_NUMBER
TO_NUMBER is an Oracle specific function for handling numerical data stored as text, often used to address text-based financial data or user input. By using the TO_NUMBER function, you can explicitly convert character strings to the NUMBER data type, enabling mathematical operations and calculations.
Basic syntax of the function is as follows:
TO_NUMBER(e1, format_model, nls_params);
e1 is an expression that you want to convert into number, which is a required argument for the function. format_model is an optional argument that you can specify the format of the string. For example:

The format_model is comprised of the number format elements listed below:
- Element: ,.
- Description: Commas and decimal points will pass through wherever they are included. Note that only one period is allowed per format mask.
- Example: 9,999,999.99
- Element: $
- Description: Leading dollar sign.
- Example: $999.99
- Element: 0
- Description: Leading and trailing 0.
- Example: 0099.99
- Element: 9
- Description: Any digit.
- Example: 999
- Element: B
- Description: Leading blank for integers.
- Example: B999
- Element: C
- Description: The ISO currency symbol as defined in the NLS_ISO_CURRENCY parameter.
- Example: C999
- Element: D
- Description: Returns the current decimal character as defined by the NLS_NUMERIC_CHARCTERS parameter.
- Example: 999D99
- Element: EEEE
- Description: Returns a value in scientific notation.
- Example: 9.9EEE
- Element: G
- Description: Returns the group separator (e.g., a comma).
- Example: 9G999
- Element: L
- Description: Returns the local currency symbol.
- Example: L999
- Element: MI
- Description: Returns negative value with trailing minus sign; returns positive value with a trailing blank.
- Example: 999MI
- Element: PR
- Description: Returns negative values in angle brackets.
- Example: 999PR
- Element: S (prefix)
- Description: Returns negative values with a leading minus sign, positive values with a leading positive sign. Note that S can appear only in the first position of a format mask.
- Example: S999
- Element: S (suffix)
- Description: Returns negative values with a trailing minus sign, positive values with a trailing positive sign. Note that S can appear only in the last position of a format mask.
- Example: 999S
- Element: TM
- Description: The text minimum number format model returns the smallest number of characters possible.
- Example: TM
- Element: U
- Description: Returns the Euro currency symbol or whatever indicated by the NLS_DUAL_CURRENCY parameter.
- Example: U999
- Element: V
- Description: Returns a value multiplied by 10n, where n is the number of 9s after the V.
- Example: 999V99
- Element: X
- Description: Returns the hexadecimal value.
- Example: XXXX
The TO_NUMBER function also has an optional third parameter, which serves to specify NLS (National Language Support) settings. The parameter allows you to reference any of the three NLS parameters listed below:
- NLS_NUMERIC_CHARACTERS = 'dg'
- 'd' is the decimal character specification and 'g' is the group separator.
- NLS_CURRENCY = 'text'
- 'text' is your specification for local currency symbol.
- NLS_ISO_CURRENCY = 'currency'
- 'currency' is the international currency symbol that you want to specify.
When included, the third parameter for TO_NUMBER is a single string that encompasses one or more of these three NLS parameters. For example:

Unlike in the United States or United Kingdom, in France or Switzerland, comma (,) is used as the decimal separator and period (.) is adopted to separate groups of thousands in large numbers. In the figure shown above, I typed 'NLS_NUMERIC_CHARACTERS = '',.''' to explicitly set the custom separators. Note that I used additional quotation marks surrounding ',.', as it is an escaping character in SQL.
TO_CHAR
The TO_CHAR function in Oracle SQL is designed to convert data from other types to character. When it is applied to a numeric value, you can explicitly convert the number value into a character string.
Basic syntax for the TO_CHAR when applied to a number is:
TO_CHAR(n, format_model, nls_params);
Where the parameter n is required numeric value, format_model is optional and comprises one or more format elements, and the nls_parms is optional that corresponds to the same parameter used in the TO_NUMBER function.
In this context, TO_CHAR transforms a numeric value n into a character string. The optional format_model provides guidance on formatting the output, allowing customization with special character, such as dollar signs or other financial symbols, handling of negative numbers, and more. For example:

Interval Functions
One of the most frequent operations involving time intervals would be subtraction. For example:

In the example above, when subtracting TIMESTAMP values from another TIMESTAMP, we see that Oracle returns the resulting values as intervals. You can also subtract intervals from each other. For example:

In the figure shown above, subtracting 8 months from 6 years results in 5 years and 4 months. Similarly, when we subtract negative 1123 minutes from 1 day, 2 hours, 3 minutes, and 4.567 seconds, we got 1 day, 20 hours, 46 minutes, and 4.567 seconds.
To convert a character string to an interval, you can use TO_YMINTERVAL and TO_DSINTERVAL functions. The TO_YMINTERVAL takes a string 'y-m', where y represents years and m represents months. Then it transforms the string into INTERVAL YEAR TO MONTHS data type. For example:

Similarly TO_DSINTERVAL converts a character string in the format required for the INTERVAL DAY TO SECOND data type, which is 'DAYS HH24:MI:SS.FF'. For example, '15 14:05:10.001' is the INTERVAL DAY TO SECOND representation for 15 days, 14 hours, 5 minutes, and 10.001 seconds. For example:

You may also need to convert a numeric value into a time interval. Oracle has NUMTOYMINTERVAL and NUMTODSINTERVAL functions for the purpose. The NUMTOYMINTERVAL(n, interval_unit) converts date information in numeric form into an interval value of time. Here, n is the numerical value that you want to convert (required) and interval_unit (required) is either 'YEAR' or 'MONTH'. For example:

Similarly, the NUMTODSINTERVAL(n, interval_unit) converts date information in numeric form (n, required) into an interval value of time (interval_unit, required). The interval_unit can be one of 'DAY', 'HOUR', 'MINUTE', or 'SECOND'. For example:



{kind=link}
0 Comments