

In computer programming, an operator is a symbol or keyword used to perform operations on variables and values, which are placed on its left and right sides, and outputs a value. On the other hand, a function takes one or more inputs (called parameters, typically enclosed within parentheses), performs a specific set of tasks, and returns an output. Regardless, both operators and functions ultimately produce a single value that can be used in further computations or logic within a program. For example, the addition operator + can combine two numbers (5 + 3 results in 8), while a function like sqrt(16) calculates the square root of a number and returns 4.
You can also use operators and functions in SQL to customize your query results. In fact, given SQL's nature as a set-based language, applying operators and functions to table columns in a query is automatically performed on all rows in the column. SQL functions with this inherent scalability is called the single-row functions, as they return one result per row processed.

In this guide, we will explore some commonly used SQL operators and single-row functions, categorized by data types, and how they perform row-level computations. Let's get started!
Single-Row Functions and Operators for Numeric Values
Single-Row Functions and Operators for Character Strings
UPPER(s1) and LOWER(s1)
If you want a string to be entirely in upper case or lowercase, you can use UPPER or LOWER functions. These functions are particularly useful for a text search. Suppose that you're searching a row containing 'nerdatandrew' from the table below:
| MY_STRING |
|---|
| Lorem ipsum |
| nerdatandrew |
| Nerdatandrew |
| oracle database |
| NERDATANDREW |
| Data science |
When retrieving data, suppose that you want to retrieve all the three rows: 'nerdatandrew', 'Nerdatandrew', and 'NERDATANDREW', but you are not sure if the data in the table is in uppercase, lowercase, or both. In such situations, you can use UPPER or LOWER function to avoid any exclusion due to the mixed cases. For example:

INITCAP(s1)
The INITCAP function converts the input text string 's1' into a mixed-case string, where the initial letter of each word is capitalized, and all subsequent characters are in lowercase letters. For example:

CONCAT(s1, s2) and s1 || s2
Oracle offers two different ways to perform string concatenation. One of the ways is the CONCAT function, which takes two string arguments. For example:

The || operator works basically the same way. The only difference is that while CONCAT function can take only two arguments at a time, the || can be repeated as many times as desired. For example:

LPAD(s1, n, s2) and RPAD(s1, n, s2)
The LPAD function pads the left side of the input character string 's1' with character string 's2', until the resulting string is 'n' characters long. Similarly, the RPAD function pads the right side of the 's1' with 's2' until 's1' reaches to the length of 'n'. Both LPAD and RPAD requires 's1' and 'n'. 's2' is optional; if omitted, 's2' defaults to a single blank space.
In practice, you would find the functions are useful in:
- Formatting Output:
- Creating reports with aligned columns.
- Displaying fixed-width data for readability.
- Data Cleaning and Preparation:
- Filing missing values with padding characters.
- Standardizing string lengths for data consistency.
- Visualizing Hierarchical Structures:
- Visualizing tree-like structures with indentation using padding.
For example, let's suppose that you have a data that looks like below:

Data stored in the file_directory table inherently has a hierarchical order. One way to visualize this is using LPAD function:

In the query above, the line 4, LPAD('-', 5 * (LEVEL -1)) || file_name AS intended_foler creates an indented representation of the data hierarchy. In the line the LPAD function takes argument '-' as 's1', 5 * (LEVEL - 1) as 'n', and 's2' is omitted. This means that it will pad '-' with blank spaces 4 blank spaces per each level of the hierarchy of the row.
LTRIM(s1, s2), RTRIM(s1, s2), and TRIM
The LTRIM and RTRIM removes any occurrences of the 's2' characters from 's1' string, from either left side of 's1' (LTRIM) or right side of 's1' (RTRIM) exclusively. In the functions, the 's1' is a required argument, whereas the 's2' is an optional argument; if 's2' is omitted, it defaults to a single blank space. These functions are quite useful when you want to strip out any unnecessary blanks, periods, ellipses, and so on. For example, to remove any trailing zeros:

The TRIM function works just same as LTRIM or RTRIM, with a slightly different syntax:
TRIM(trim_info trim_char FROM trim_source);
where:
- trim_info should be one of these keywords: LEADING, TRAILING, BOTH
- If omitted, defaults to BOTH.
- trim_char is a single character to be trimmed.
- If omitted, assumed to be a blank.
- trim_source is the source string
- If omitted, the TRIM function will return a NULL.
For example:
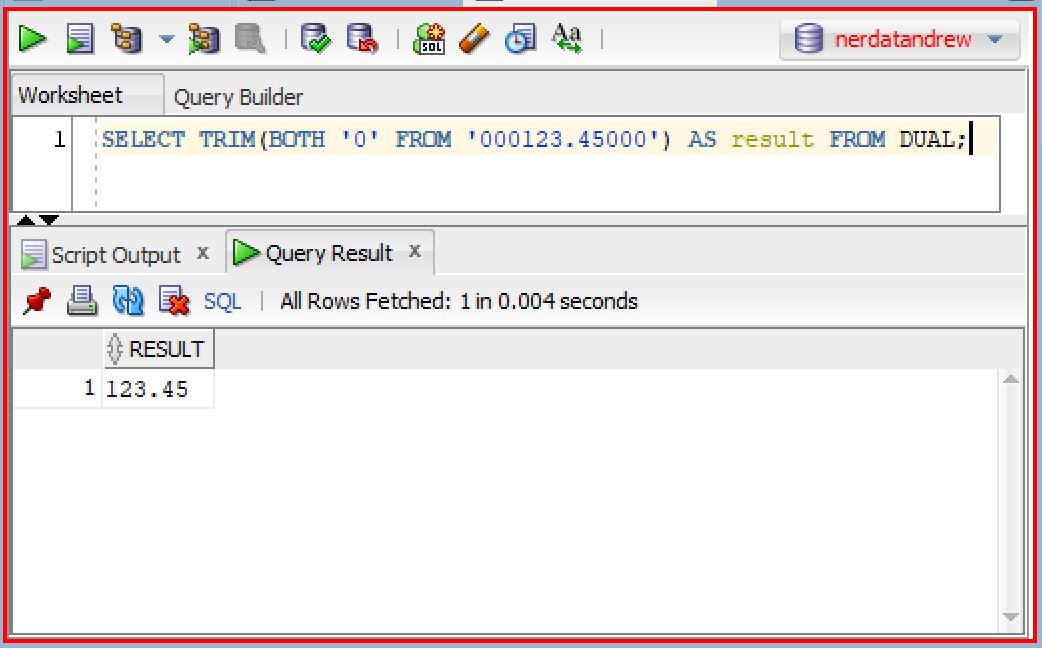
LENGTH(s)
The LENGTH function returns the number of characters in a given text string value. For example:

INSTR(s1, s2, p, n)
The INSTR locates where a substring 's2' is in the source string 's1'. Both 's1' and 's2' are required in the function. Optionally, you can also specify the starting position in 's1' to start looking for occurrences of 's2' by 'p', and the number of occurrences of 's2' to locate by 'n'. For example, suppose that you want to look for the string 'is' within 'Mississippi', starting at the first character position, but looking for the second occurrence of 'is'.

The INSTR function is telling us that the second occurrence of 'is' starts at the fifth character in 'Mississippi'.
SUBSTR(s, p, n)
The SUBSTR extracts a substring from its input string 's' (required), starting at the specified position 'p' (required), and continuing for 'n' number of characters (optional). If the length 'n' is omitted, then the substring starts as 'p' and runs through the end of 's'. For example:

Note: Indexing is one-based. For example, in a string 'Hello, Oracle!', the index for the first character H is 1, not 0.
SOUNDEX
SOUNDEX is a phonetic algorithm used to index names based on their pronunciation, rather than their spelling. It was developed in the early 1900s by Robert C. Russell and Margaret King Odell to help researchers find records with potentially misspelled names in large datasets. Oracle supports a built-in function to implement the SOUNDEX algorithm in SQL.
| Letter | SOUNDEX Code |
|---|---|
| B, F, P, V | 1 |
| C, G, J, K, Q, S, X, Z | 2 |
| D, T | 3 |
| L | 4 |
| M, N | 5 |
| R | 6 |
| A, E, H, I, O, U, W, Y | Ignored |
Based on the coding scheme above, here's an example illustrating how to use the SOUNDEX function in Oracle SQL:

In the example above, two strings 'Smith' and 'Smythe' have similar pronunciations. It is likely the second string 'Smythe' is misspelled by data entrance. Occasionally, we want to retrieve all data containing both the correct name, Smith, and potentially misspelled one Smythe. In such cases, the SOUNDEX function would be very helpful.
When generating a SOUNDEX translation, the first letter of the input string remains unchanged. Then the subsequent letters are systematically translated into numeric codes based on the phonetic rules in the table shown earlier. The translation goes for three digits; any remaining letters beyond those used for the three digits are disregarded. The resulting four-character code, comprised of the original first letter and the three digits, serves as a phonetic representation of the string, emphasizing sound over exact spelling.
For example, in the case of 'Smith' and 'Smythe', the first character 'S' is preserved for both strings. Then the following m is encoded to 5, i and y are ignored, t is encoded to 3. The remaining h and e are also ignored according to the coding scheme. To ensure the length of the results, 0 will be padded to the output S53.
One place where we can find the SOUNDEX is useful in practice would be the WHERE clause. For example, let's consider a table below:
| TRAINER_ID | FIRST_NAME | LAST_NAME | HOMETOWN | JOURNEY_STARTED |
|---|---|---|---|---|
| 1 | Ash | Ketchum | Pallet Town | 01-APR-96 |
| 2 | Misty | Waterflower | Cerulean City | 15-FEB-97 |
| 3 | Brock | Pewter | Pewter City | 10-JUL-98 |
| 4 | Paulo | Antrim | Pallet Town | 23-JUL-01 |
| 5 | Grigory | Anderson | Pallet Town | 16-AUG-01 |
| 6 | Carole | Anderson | Pallet Town | 26-JUN-02 |
Now, suppose that you want to retrieve trainers from the table whose last name sounds like "Andrew":

The query above fetches every records from tbl_employee table whose last name sounds like Andrew. Thus, although strings Antrim and Anderson does not exactly match with Andrew, we can retrieve those rows.
It is worth noting that the SOUNDEX is case-insensitive and is designed for use with American English. So, it won't work quite as well with words originated from other languages, whose pronunciation rules and practices are different. For example, a Vietnamese name Nguyen is pronounced "Nwen", but the SOUNDEX patterns for the two string Nguyen and Nwen are different.
Single-Row Functions and Operators for Datetime and Intervals
They support calculations on datetime columns and accurate analysis of time-based data. For example, suppose that you want to figure out 5 months ahead from today:

Since the number of days varies by month and year, using intervals proves to be much clearer and easier as shown in the figure above
ROUND(d, i) and TRUNC(d, i)
When the ROUND function is applied to a date value (denoted as 'd'), it rounds off the value based on a specified level of detail ('i'). 'd' is a required argument on which you wish to perform operations, and 'i' is an optional format model that dictates the precision to which 'd' should be rounded; if 'i' is omitted, ROUND will round 'd' to the nearest whole day by default.

In the example shown above, '2023-05-31' rounded down to month ('2023-06-01') and year ('2023-01-01'). The desired output formats are specified with 'YYYY' and 'MM'. Similarly, when the ROUND function is applied to '2023-12-31', we can observe that the value is rounded up to the specified level, which is '2024-01-01'.
Note: For ROUND function, values are biased toward rounding up. For example, when rounding off time, 12 noon rounds up to the next day.
The TRUNC function shares both the required and optional arguments with ROUND, and it serves the similar purpose as ROUND when applied to dates. However, unlike the ROUND function, which returns rounded date and time values, TRUNC consistently disregards (rounds down). For example:

In the figure shown above, we can observe that the date value '2023-12-31' is truncated to the first day of the month and year, which is different from the output of the ROUND function.
NEXT_DAY(d, c)
The NEXT_DAY function takes two required arguments: a date string 'd' and another string 'c', indicating the day of the week. Then it returns the first occurrence of the c day after the date in d. For example, to calculate the first Sunday comes after March 25th in 2024 in Oracle SQL:

LAST_DAY(d)
The LAST_DAY function in Oracle SQL requires one argument, 'd', a date string. The function returns the last day of the month in which the specified date 'd' is situated. For example:

ADD_MONTHS(d, n)
The ADD_MONTH function in Oracle SQL takes two required arguments: a date string 'd' and a whole number 'n'. This function adds 'n' months to the input date 'd'. For example:

In the figure shown above, I added and subtracted some months to date strings. Note that, in Oracle, there is no distinct function to subtract months. Instead, just add a negative number of months in ADD_MONTHS function.
MONTHS_BETWEEN(d1, d2)
The MONTHS_BETWEEN function calculates the number of months between the two date values, requiring both 'd1' and 'd2' as required parameters to determine the duration in months between the specified dates. For example:

In the example above, I input '2026-12-01' as 'd1' and '2024-03-01' as 'd2'. Then the MONTHS_BETWEEN determines how many months pasts from 'd2' to 'd1'. So, if you input the date values in a chronological order, you will see a negative value. For example:

Note that the MONTHS_BETWEEN function does not round off the resulting value automatically; if the result is a partial month, it will show you a real number. For example:

EXTRACT(field FROM source)
The EXTRACT function extracts a specific component, such as year, month, day, hour, etc., from a DATE or TIMESTAMP value. It offers a direct and convenient way to isolate specific components without needing other functions or conversions. The function takes two arguments, 'field' and 'source', where 'field' specifies the component to extract, and 'source' is the DATE or TIMESTAMP value from which to extract the component. In between the two arguments, you should also place the FROM keyword. For example:

WHERE
The WHERE Clause
The WHERE clause acts as a filter for your data, allowing you to work with only the specific rows based on the defined conditions. It plays an important role not only in a SELECT statement, but also in the UPDATE and DELETE statements, as it allows you to narrow down the records that you want to update or delete.
Within a SELECT statement, the WHERE clause, if used, always comes after the FROM clause. Then after the reserved word WHERE, you can specify your condition for your needs. The condition consists of expressions including one or more comparison operators. Then Oracle will evaluate each row to be true or false in a table specified in the FROM clause. Since Oracle did not restrict any columns in the table, the conditions in your WHERE clause not necessarily has also to be in the SELECT clause. To learn more, please see this post.
To illustrate how it works, let's consider a table structured as follows:

Now, suppose that you want to retrieve menu item, serving size, calories, as well as data updated timestamps, where category value is 4204 and restaurant name is 'Subway'. You can achieve this as follows:

In the query shown above, I specified criteria as category_id equals to be 4204 and restaurant_name equals to be 'Subway'. Then Oracle filters out rows by criteria and include only those satisfying the criteria. Consequently, the retrieved data has only 6 rows.
Note that the columns specified in the WHERE clause not necessarily has to be in the SELECT clause. For example, in the query shown above, while category_id and restaurant_name is used for filtering criteria, the SELECT clause does not include the two columns. By the logical order of clauses in a SELECT statement, WHERE comes before SELECT clause. To clarify, the logical order in terms of processing is as follows:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
Thus, at the moment when Oracle filters out rows by WHERE clause specification, every columns defined in the FROM clause are available. To learn more, please see this post.
Comparing Expressions
The WHERE clause involves a set of comparisons, each evaluating each row to be true or false. For a comparison operator, both operands on either side should ideally be of the same data type. Numeric, character string, and date are the three general categories of data types to consider when applying the comparison operators.
- Numeric: Smaller numbers are less than larger numbers.
- Character: Uppercase letters are less than lower case letters. Be cautious with numbers stored as character strings. For example, a character string '2' is considered to be greater than the string '10', as the first character of '10' is '1' and it comes before '2' in a alphanumeric order.
- Dates: Earlier dates are less than later dates.
Comparison Operators for Numeric and Date time Data
- = : Equal to.
- > : Greater than.
- < : Less than.
- >= : Greater than or equal to.
- <= : Less than or equal to.
- <> ^= != : Not equal to.
- BETWEEN numeric_value1 AND numeric_value2: Filter values based on a range of values.
Note that the BETWEEN numeric_value1 AND numeric_value2 is inclusive in both sides. That is, if a row's value in the specified column is equal to either numeric_value1 or numeric_value2, it will be included in the result set. For example:

In the figure shown above, we see that the returning dataset narrowed down by the BETWEEN includes rows with calories at both boundaries.
The comparison operators work in a similar way for the date time data. The comparison operators >, >=, <, <=, =, <> compare two dates based on their chronological order. Keep in mind the rule: the later days are greater days! For example, let's suppose that you want to fetch all the rows that were updated between January 15 and 20, 2024:
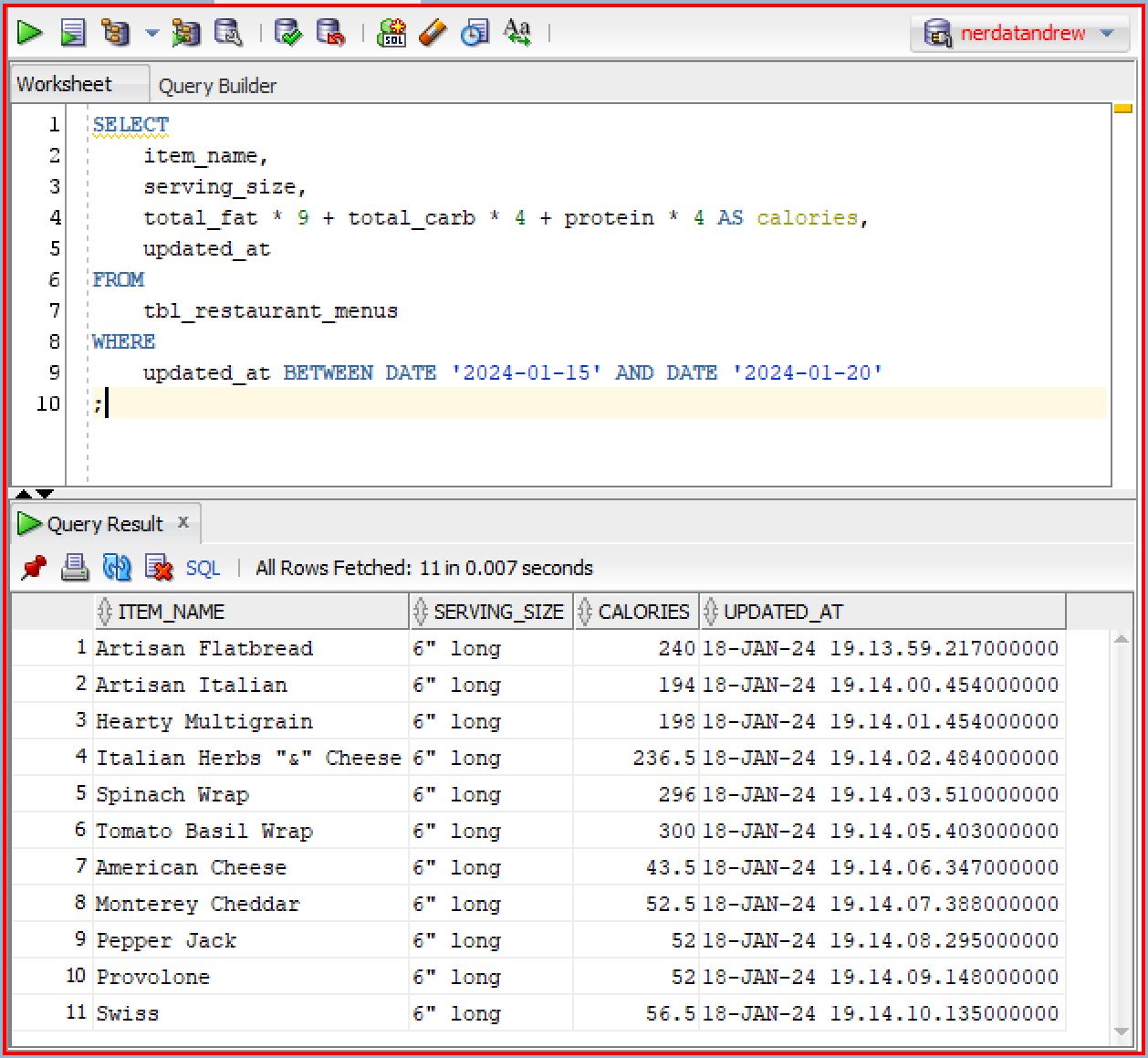
Comparison Operators for Character Strings
When a comparison operator is applied to character strings, Oracle performs comparison character-by-character, starting from the leftmost position. It determines the result based on the first mismatching characters. For example:

If you look at the line 1 and 2 in the figure shown above, Oracle compared two character strings '12' and '2', character-by-character. When it encountered '1' and '2' at the left most position, Oracle evaluates '1' is less than '2', and thereby we got no result for the first query and 'True' for the second query. Similarly, at the line 3, Oracle determined 'apple' is less than 'apple pie', because the former one doesn't have trailing sequence of characters. In line 4, we can also observe that a comparison between character strings is case-sensitive.
Wildcard Searches on Characters and LIKE Operator
In addition to the comparison operators, you can use the LIKE operator to search a specified pattern in a character column. The syntax for using the LIKE operator is as follows:
SELECTcolumn1, column2, ...FROM table_nameWHEREcolumnN LIKE pattern;
Here, columnN is the name of the column you want to search, and pattern is the text you are searching for. The pattern can include wildcards such as % and _. The % wildcard matches any string of zero or more characters. On the other hand, the _ wildcard matches any single character. For example:

In the query shown above, Oracle retrieved all the rows with item_name starts with a pattern 'American'.
Logical Operators: AND, OR, NOT
In addition to the comparison operators, you can also use the logical operators to create compound conditions in your expressions. AND, OR, and NOT allow you to combine multiple conditions to filter data more precisely.
- AND:
- Returns true if both conditions are true.
- Used to select rows that meet all specified criteria.
- OR:
- Returns true if at least one of the conditions is true.
- Used to select rows that meet any of the specified criteria.
- NOT:
- Inverses the result of a condition, returning true if the condition is false and vice versa.
- Used to negate conditions.
Precedence between the logical operators is NOT, followed by AND, and then lastly OR. If the operators have the same precedence, then Oracle evaluates from the left to the right. To override the precedence, you can use parentheses. For example:

In the query shown above, Oracle evaluates the expression UPPER(type1) = 'PSYCHIC' OR UPPER(type2) = 'PSYCHIC' first, as it is inside parentheses. So, among the rows at least one of type1 or type2 equals to 'PSYCHIC' will then be evaluated if it has is_legendary value equals to 1.
In practice, it is common to use INITCAP, LOWER, or UPPER function in a search criterion, especially when you are not sure, if the stored string values have consistent cases. This ensures that no rows will be excluded because of any case-inconsistency.
Membership Operators: IN vs. OR
The IN operator in SQL functions similarly to the OR operator, determining whether at least one of multiple condition is satisfied. If a given value matches at least one member in the specified list, SQL returns TRUE; otherwise, it returns FALSE. For example:
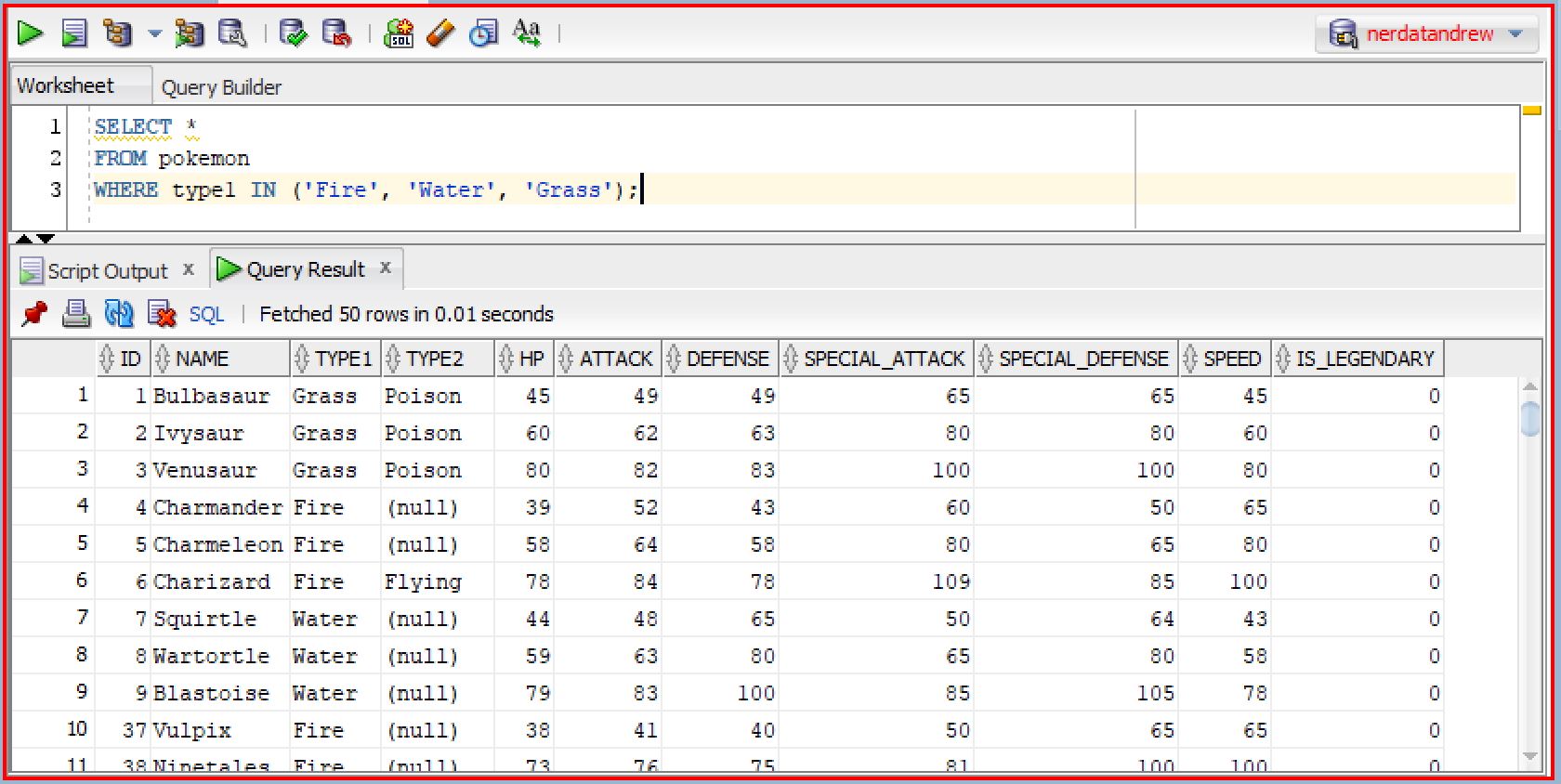
The query above retrieves records with type1 equal to 'Fire', 'Water', or 'Grass'. So, basically the query below retrieves the same result.

However, despite their similarities, there are major differences in functionality and performance between the IN and OR operators. The IN operator checks if a value exists within a set of values, providing a more concise and efficient approach, especially when dealing with a large number of values. It leverages indexing to swiftly determine value existence within the set.
On the contrary, the OR operator checks if a condition is TRUE for at least one of several expressions, requiring separate evaluation for each expression. In general, the IN operator is faster and more efficient than OR when handling an extensive range of values. This is because IN can use an index to quickly check if a value exists within a set, while OR has to evaluate each expression separately.
IS NULL and IS NOT NULL

This is because, in Oracle, NULL is considered as an unknown value. Thus, expressions like = NULL would be interpreted as "equals to an unknown." While there are NULLs, since there are no "unknowns" in the stored data, the resulting set from the query shown above has no row. In other words, Oracle interprets such expressions as "is the value known and equal to NULL?". To correct this:

Reporting Aggregated Data Using the Group Functions
The Use of Aggregate Functions
In Oracle, aggregate functions are designed to yield a single value for a logical set of rows. These functions scan a specific set of rows, process the data, and then produce an output. For example:

The SQL query above is counting the number of unique values in the type1 column of the pokemon table. The number of values determined by the DISTINCT keyword is 18, and each value is a character string. So, the COUNT function takes 18-character strings in the query above. Then it returns a single numeric value.
Here are some commonly used group functions in daily practice:
- COUNT(): Counts the number of rows in a result set or the number of non-null values in a specific column.
- SUM(): Calculates the sum of values in a numeric column, ignoring NULL values.
- AVG(): Computes the average of values in a numeric column, ignoring NULL values.
- STDDEV(): Computes the sample standard deviation in a numeric column, ignoring NULL values.
- MIN(): Retrieves the minimum value in a column, ignoring NULL values.
- MAX(): Retrieves the maximum value in a column, ignoring NULL values.
For example:

In this example, I aggregated data across the entire dataset without specific grouping. Note that the functions in the query shown above ignores any NULLs in their calculations.
The GROUP BY Clause
In the context of data aggregation, you can also have different levels of summarization base on one or more column values. When you use the GROUP BY clause, you are essentially creating group of rows that share the same values in the specified columns. Each unique combination of values in the grouped columns represents a grouping level. For example, let's consider a query below:

In this example, the grouping level is the 18 unique values of the type1 values of the Pokémon. Within each type1 value, Oracle calculates the number of Pokémon, average combat points, and etc. To introduce a new level of aggregation, you should specify the associated column in the GROUP BY clause. For example:

When aggregating data, it is important to ensure that the columns in the SELECT clause match the corresponding grouping levels specified in the GROUP BY clause; otherwise, Oracle will throw an error. For example:

In the query above, I included two new columns: type1 and type2 and Oracle successfully retrieved desired output: each row has a combination of type1 and type2 values, alongside with the combat power calculations. However, what if I include the name of each Pokémon, which has a grouping level outside of the specifications in the GROUP BY clause?
As you might have expected, Oracle throws an error and says "not a GROUP BY expression." This indicates that we're trying to use an expression in the SELECT clause, but it is not included in the GROUP BY clause. In this example, the expression, name, is the name of each Pokémon, and within a unique combination of type1 and type2 values, there are multiple Pokémon names available. However, unlike the combat power values, there is no single summarization of Pokémon names. Consequently, Oracle faces ambiguity in determining on which group of Pokémon types each name of Pokémon is based.
To address this, ensure that any non-aggregated expressions in the SELECT clause, like the Pokémon name in this case, are included in the GROUP BY clause. This allows Oracle to correctly group the data before applying aggregate functions, resolving the "not a GROUP BY expression" error and providing accurate query results.
The HAVING Clause
In Oracle SQL, the HAVING clause filters the results of a query based on aggregate values. You might question the need for a distinct HAVING clause instead of relying solely on the WHERE clause. To answer this question, let's recall the lexical and logical order of each clause in a SELECT statement. The syntaxial order of clauses in a SELECT query is:
SELECT column1, aggregate_function(column2)FROM tableWHERE conditionsGROUP BY column1HAVING aggregate_function(column2) condition;
However, Oracle handles the clauses in a query with the following order:
- FROM: Firstly, retrieves data from a table specified in the FROM clause
- WHERE: Narrow down the results from the first step.
- GROUP BY: Then set logical groups with the GROUP BY clause.
- HAVING: Performs filtering based on the condition.
- SELECT: Finally, the SELECT clause determines the specific columns and expressions to be included in the final result set.
Thus, at the moment when the WHERE clause filters out individual rows, the aggregated values defined in the GROUP BY clause is not known yet. To filter out the aggregated values, we need a separate HAVING clause following the GROUP BY clause. Here's an example usage of a HAVING clause:

In this example, I filtered out the aggregated records with the HAVING clause. We got one row in the result set, after excluding the rows with aggregated max CP greater than 200. Note that we cannot use the alias defined in the SELECT clause. This is also because of the logical order of the clauses; the SELECT clause comes after the HAVING clause. Thus, the column alias defined with the AS keyword in the SELECT clause is not known at the point when Oracle executes the HAVING clause.
Single-Row Functions
dfads
fdasf
The function FROM_TZ function converts a timestamp literal into a specific time zone. For example:

The AT TIME ZONE operator converts a TIMESTAMP value on its left-hand side to the time zone on its right-hand side. For example:
Aside: SYSDATE and LOCALTIMESTAMP
The SYSDATE is a special variable that holds the system's current date and time. When you print out SYSDATE in a SELECT statement, it will show you DATE type value, which is in the format 'DD-MON-YY'.
The SYSDATE is based on the server's system clock where Oracle database is installed. So, even when your SQL statement is running on an instance from a remote client location, SYSDATE will return the date and time of the operating system on which the server resides.
LOCALTIMESTAMP is an automatic variable that stores the current timestamp value for the user. For example:
Nulls
In Oracle Database, a NULL value indicates that a particular column in a row has no data or an unknown value. Nulls can appear in columns of any data type that are not constrained by NOT NULL or PRIMARY KEY integrity rules. Oracle Database treats a character value with a length of zero as a NULL.
However, unlike some other languages, Oracle's NULL is not equivalent to the numeric value of zero. So, it is important to avoid using NULL to represent zero. Using zero clearly communicates that there is a quantity of none, whereas NULL can be ambiguous, which can cause unexpected results in calculations and logical operations, leading to errors. The behavior of NULLs depends on the context and requires operators and functions specifically designed to handle them.


{kind=link}
0 Comments