

Oracle SQL functions can be categorized into three main types: scalar, aggregate, and analytical functions. Scalar functions take one row at a time and a single result for each row processed. On the other hand, aggregate functions are applied to multiple rows and return a single result.

Analytical functions reside somewhere between these two categories. They operate on a set of rows related to current row. These functions allow you to perform calculations across a specific range of rows, known as a "window," without grouping the result set. Here, a window can be defined by the number of rows or by any other logic, such as a time range. As the processing moves from one row to another, the window may slide, depending on how the analytical function specifies the window.
In terms of logical order of data processing steps in a SELECT statement, analytical functions fall between SELECT and ORDER BY clause. That is, Oracle will firstly fetch data defined in FROM clause, narrow down by WHERE clause, remain only listed columns in SELECT clause, then handle an analytical functions. For this reason, you cannot include any analytic functions anywhere other than SELECT list or the ORDER BY clause: they are not allowed in the WHERE, HAVING, and GROUP BY clause.
For example, let's consider a table shown in the figure below:

Table above has four different columns to store and manage Pokémon experience values that I've gained from a game. So, how we can summarize this table? Well, we can use the SUM as an aggregate function to obtain the total amount of experiences. For example:

This query retrieves the pokemon_id and name columns from the joined tables and adds an additional column, "Total Exp. Gained," which represents the total sum of experience_gained over the records in the window specified by the OVER clause. Here, I didn't add any window logic in the OVER clause. Thus, it will sum over all experience_gained column values throughout the table.
What if we want the total experience gained by each Pokémon? We can add a partitioning logic with the PARTITION BY keyword. For example:
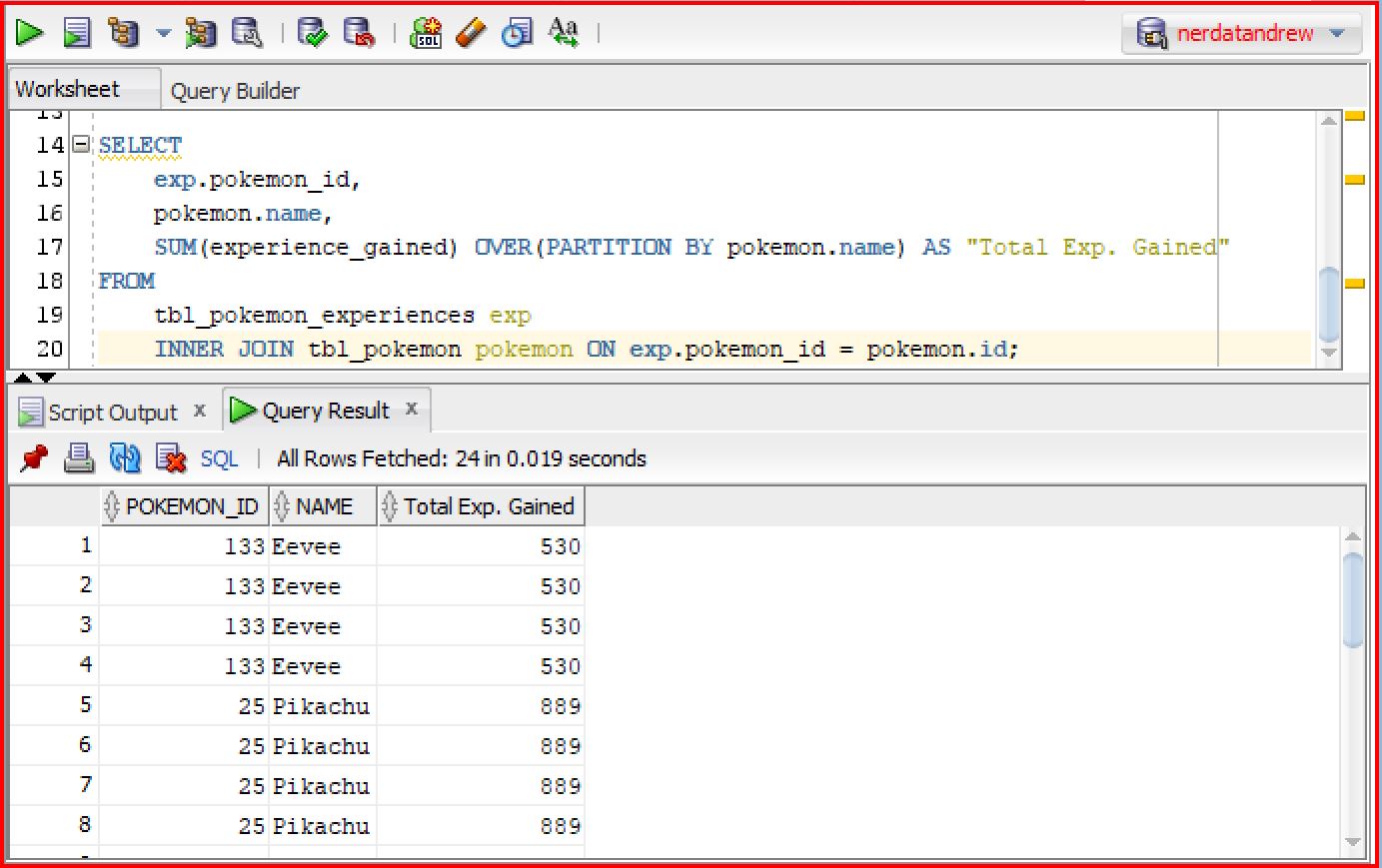
This time, the sum is calculated within partitioning windows defined by the pokemon.name column. The PARTITION BY clause creates partitions based on the values in the specified column. Consequently, the sum is computed separately for each partition, allowing for separate calculations for each Pokémon.
We can go further and calculate percentages within each partition. For example:

This SQL query summarize the total experience gained within partitions based on Pokémon names, and then calculates the percentage of experience gained relative to the total experience for each Pokémon name.
Lastly, let's see how it works if we specify more than one columns in the PARTITION BY clause. When there are multiple columns in the PARTITION BY clause, we are partitioning the result set based on each distinct combinations of column values. This means that the analytic functions, such as SUM or AVG, will be applied separately for each unique combination of the specified columns. For example:

Here, PARTITION BY pokemon.name, exp.gained_from creates partitioning window based on unique combinations of the two column values: ('Eevee', 'Trainer battle'), ('Pikachu', 'Trainer battle'), ('Pikachu', 'Wild'). The SUM function is then applied within each of these partitions, calculating the sum of experience_gained separately.
Imagine a situation where you're managing a score keeping system for games. Providing the cumulative sum of scores to the players would be necessary for maintaining the system. In this context, running totals refer to the progress of a variable over time or across a sequence of events. For example, consider a table as follows:

Now, let's say that you want to obtain a running total of experience_gained column for each record. That is, you aim to calculate the cumulative sum of the column up to the current row, providing a continuously updated total as you traverse the result set. You can achieve this as follows:

This query calculates the running total as well as total experience gained for each Pokémon, considering the order of timestamps. In the query, lines 4 and 5 both using the SUM window function, but with different OVER clauses, resulting in different calculations. Let's break down the difference between these two lines:
- Line 4: "Running Total of Exp. Gained"
- This calculates the running total of the experience_gained column within partitions defined by pokemon.name. The ORDER BY gained_timestamp ensures that the running total is calculated in the chronological order of the gained_timestamp.
- Line 5: "Total Exp. Gained"
- This simply calculates the total experience gained for each Pokémon name separately. Unlike line 4, it does not consider order of the gained_timestamp column. Consequently, output is the sum of experience gained for each Pokémon across all records without regard to the order in which the experiences were gained.
In summary, to obtain a running total of a column in Oracle SQL, you should use the SUM window function combined with ORDER BY specification. This ORDER BY clause ensures that the running total is calculated in the specified order, typically based on a timestamp or any other column that defines the order in which the data should be considered.
Of course, you can use some other functions in conjunction with the OVER clause. For example, if you use AVG function, you'll obtain moving average of a time series column.

ROWS BETWEEN n1 PRECEDING and n2 FOLLOWING

Let's consider a table shown in the figure above. The table has five columns: "National Pokedex No.," "Pokemon Name," "Type 1," "Type2," and "Total Base Stat". Now, suppose that, for each row, you want to calculate the average total base stats with one preceding to one following rows. One way to achieve this with Oracle SQL is to add a ROWS clause in the OVER clause. For example:

Code lines from 15 to 16 computes the average base stat using an analytical function with rounding to two decimal places. The PARTITION BY clause divides the result set into partitions based on the type_1 column values. The ORDER BY clause sorts the rows within each partition by the id column in an ascending order.
Then the ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING defines a window of rows to consider for the average calculation. This range includes the current row and its adjacent. So, for example, if you look at the Avg. Base Stat of Metapod, we see that the calculated value is the average of 195, 205, and 395.

The figure shown above clearly illustrates how it works. For the first row in the table, there is no preceding row available. So, it calculates the average with the current and its following. Then it slides down the row partitioning window to the next three. This time, the query calculates the average for the preceding, current, and the following.
Window sliding keep moving on until it encounters the very last row defined by PARTITION BY clause. Then at the very last row, where there is no following is available, the window function calculates the average of the available two rows. For example:

CURRENT ROW and UNBOUNDED
Of course, the number of preceding and following rows are not limited to one. You can specify any number of rows for the two positions, including 0. Entering 0 for either PRECEDING or FOLLOWING means the current row. For example:

Alternatively, you can also use keyword CURRENT ROW. For example:

The keyword UNBOUNDED can be used to specify a range as far as the partition goes. For example:

In the query shown above, the PARTITION BY type_1 divides the result set into partitions based on the type_1 column. The ORDER BY id sorts the rows within each partition by the id column. Then the ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING clause defines a window of rows to consider the average calculation. Here, the window includes the current row and all rows following it. For example, if you look at the row for Vivillon, the calculated average is 411, as the current row value is 411 and there is no following rows.


{kind=link}
0 Comments