

From a statistician's perspective, data can be defined as a collection of column vectors, each containing observed values. These columns are referred to as variables, as their values vary depending on the observation (or row) they represent. Collectively, the column vectors form a tabular structure, which is known as a dataset.
Being a "Statistical Analysis System," SAS organizes data into a tabular structure with columns and rows, referred to as a SAS dataset. This is the only data structure that SAS can process; you cannot apply any SAS procedures directly to external data formats like CSV or Excel files without first importing[1] them into a SAS dataset.
The DATA step is a block of SAS statements used to create a new SAS dataset[2]. This step begins with the keyword DATA, followed by the destination file name using dot notation (SAS library and data set name, separated by a period). Optionally, you can add some options to specify where and how to reference the raw data source.
SAS statements under the block provide instructions on how to interpret the data source and format the new dataset, such as specifying variable names, applying column operations, filtering rows, or column aggregations. Lastly, a RUN statement should be placed to execute the current DATA step.
DATA mydata.dataset;<Some instructions for creating dataset>;RUN; /* Executes the DATA step */
SAS data sets must adhere to the following naming rules:
- Names must be 32 characters or fewer in length.
- Start with an alphabet (A-Z, a-z) or an underscore (_).
- Following the first character, names can contain alphabet, numbers, or underscore.
- Data set names are not case sensitive.
If you omit the library name, the output dataset will be saved in the temporal WORK library. SAS automatically deletes all datasets in the WORK library at the end of the current session. To avoid this, please make sure that you specify the library name.
DATA Step Basics
Understanding SAS Program Data Vector
Before proceeding, it is worth discussing how SAS creates a dataset behind the scene. When creating a new dataset, for each data line from the reference, SAS first generates an empty structure known as the Program Data Vector (PDV). This is a temporal space where SAS populates values by executing provided DATA step statements. Once SAS has executed all the statements for the current observation, the populated PDV is added to the new dataset as a new observation. This process will be repeated for each row in the data source until all observations are processed.
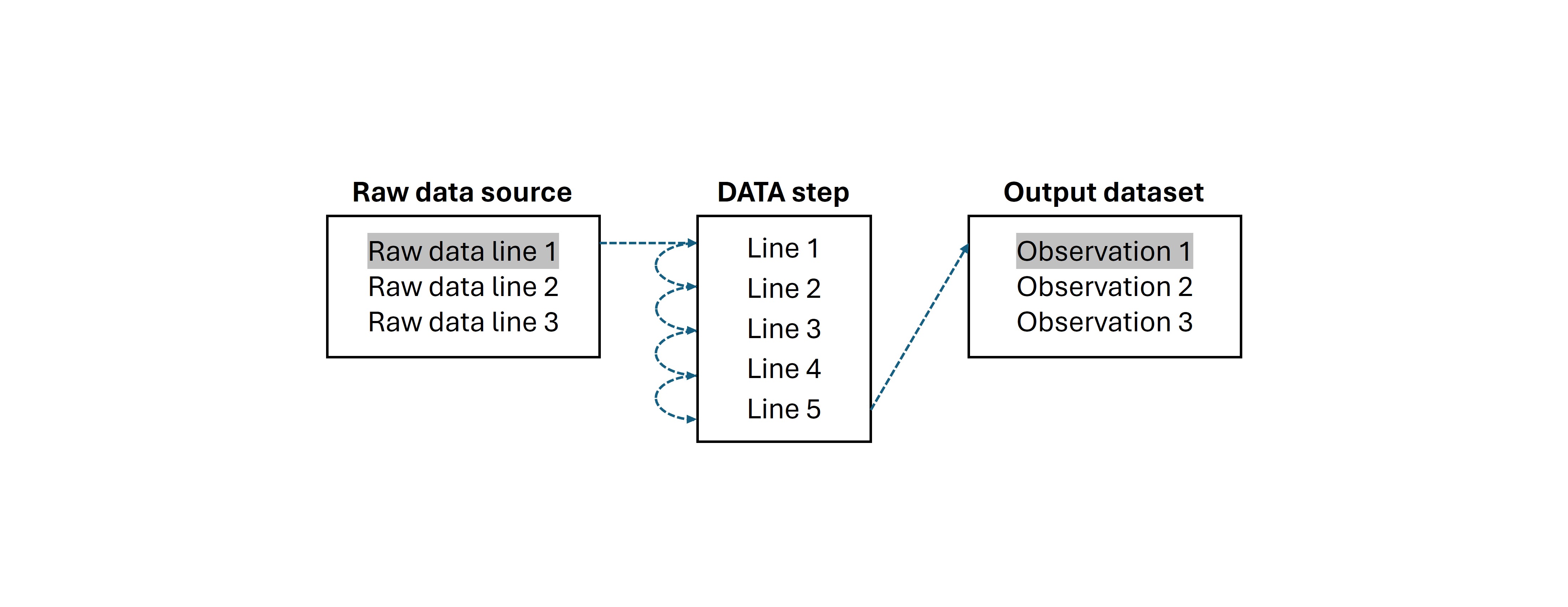
For example, let's suppose that you're creating a SAS dataset using the following text file as a reference:

This file contains five rows and five columns, with values separated by spaces. Then the following DATA step is submitted to create mydata.sales:
DATA mydata.sales;INFILE '/home/u63368964/source/sales.txt';INPUT transaction_id date :yymmdd10. product $ quantity sales_amount;RUN;
When you run this step, SAS will first prepare a PDV with a length of five, allocating one for each column. Then the PDV is populated based on the first row values using the subsequent SAS statements, which is the INPUT statement in this example. This process is repeated for each row until the last row is reached.

After execution, the output dataset will appear in the "OUTPUT" tab. We see that the data values are organized into a tabular structure with five columns and five rows. In SAS terminology, the columns are referred to as variables and the rows as observations. Each variable must have a unique name, length, and data type (numeric or character), which determine how data values are stored and processed.
The INPUT statement in a DATA step is used to read and assign values to the variables. In this example, observe that a dollar sign ($) is placed after product. This indicates the values in the third column should be interpreted and stored as a character string. Similarly, :yymmdd10. specifies that the values in the second column are date strings with a length of 10 characters.
Manual Entry of Raw Data Values
When writing a test case for your SAS program, you probably include only a small number of observations. For the purpose, it is convenient to directly input the data values into your SAS program script. To indicate SAS that the raw data values will be provided inline, after adding the INPUT statement to specify the variable attributes, you should place the keyword DATALINES or CARDS[3]. Any following lines comes after the keyword will be considered as the data entry. For example:
DATA sales;INPUT timestamp :datetime. exercise $ reps sets weights;DATALINES;27MAR2023:08:00:00 Squats 10 3 10027MAR2023:08:15:00 Push-ups 15 3 027MAR2023:08:30:00 Bench-press 8 4 12027MAR2023:08:45:00 Deadlifts 12 3 15027MAR2023:09:00:00 Lunges 10 3 8027MAR2023:09:15:00 Pull-ups 8 4 027MAR2023:09:30:00 Bicep-curls 12 3 4027MAR2023:09:45:00 Planks . . .27MAR2023:10:00:00 Shoulder-press 10 3 50;RUN;
In the DATALINES block, for each observation, the data entries should be delimited by a space and any missing values should be marked by a period. SAS stores each delimited value to its destined variable. For example, the first data line, 27MAR2023:08:00:00 Squats 10 3 100, consists of five data values separated by spaces. Thus, the first value, 27MAR2023:08:00:00, will be stored as the first observation of the Timestamp. Similarly, the second value, Squats, will be stored as the first observation of the next variable, Exercise, and so forth. (The :DATETIME is called an informat, telling SAS how data entries are formatted.)

When
Importing External Data Files into SAS Data set
Most of the time, you will create a new data set by referencing an existing data file, which could be formatted as CSV, Microsoft Excel, or any other text file. To inform SAS that the raw data values will be sourced from an external file, you should add an INFILE statement with the file directory before the INPUT statement.
If you're working in SAS Studio, you should first upload the local file and then provide the file directory of the uploaded data file. For example, let's consider data values stored in your local machine as follows:

After uploading the file through the "Upload" button on the navigation pane, you can right-click on the file and select "Properties." Then SAS Studio opens a dialog with the exact location of the uploaded file.

Using the file location, you can import the uploaded file into a SAS data set in a DATA step:
DATA MyData.PowerConsumption;INFILE '/home/u63368964/source/household-power-consumption.txt' DLM=';' FIRSTOBS=2;INPUT Date :ANYDTDTE10. Time TIME8.GlobalActivePower GlobalReactivePower Voltage GlobalIntensitySubMetering1 SubMetering2 SubMetering3;RUN;
Controlling Inputs with the INFILE Options
When reading data from external sources through an INFILE statement, you can include some options to control data inputs. To add an INFILE option, simply append it after file directory, separated by a space. Below are commonly used INFILE options:
- FIRSTOBS: Specifies the row number from which SAS begins to read data.
- OBS: Specifies the row number at which SAS finishes reading data.
- ENCODING: Specifies the character encoding of the file. Common encodings include 'latin1', 'utf-8', etc.
- DLM: Short for "delimiter." It specifies the character that separates values in the file. SAS defaults to using a space as the delimiter, but you can specify others like comma (',') or tab ('\t'), depending on the source data format.
- DSD: The "Delimiter Sensitive Data," or DSD, is an option to handle situations where data values in a delimited file contain the delimiter within the actual data. For example, consider a data file delimited by commas have a character string: "John Doe","123, Main St",25. Without DSD, SAS interprets this as four values. To prevent this, you can specify DSD=',' to ensure that SAS recognizes the entire quoted string as a single value.
- MISSOVER: By default, SAS automatically moves to the next line to read next values, if SAS reached the end of the data line while there are remaining variables to fill in. The MISSOVER option tells SAS that if a data line runs out of value, assign missing values to the remaining variables.
- TRUNCOVER: When the raw data file is fixed formatted with some trailing missing values, specifying TRUNCOVER option tells SAS to read data for the variable until it reaches the end of the data line or the last column specified in the format, whichever comes first.
For example, let's consider a text file delimited by commas as shown below. In the DATA step, we would like to read from the second to the seventh data line, excluding both the headers and comments. Also observe that the third and fifth rows exhibit trailing missing values, which have been truncated.

The following DATA step imports this data file into a SAS data set:
DATA MyData.HomeAddress;/* Specifying variable lengths */LENGTH ID $3 Name $50 Age 3 Sex $1 Address $100;INFILE '/home/u63368964/source/home-address.dat' ENCODING='utf-8' FIRSTOBS=2 OBS=7 DLM=',' TRUNCOVER;INPUT ID $ Name $ Age Sex $ Address;RUN;

Creating a Data Set Bringing Observations from Another SAS Data set
Often, you want to create a SAS data set referencing from another data set. The SET statement brings observations from the specified data set and creates a new data set. For example:
DATA JapaneseAddress;SET MyData.HomeAddress;PostalCode = SUBSTR(Address, 1, 11);DROP ID Age Sex;RENAME Name = HouseholdName;RUN;
This example DATA step creates the JapaneseAddress, referencing from Mydata.HomeAddress. After bringing all observations from MyData.HomeAddress, the DATA step creates a new variable by applying SUBSTR function to the Address variable. It also drops unnecessary variables using the DROP statement and renames Name by the RENAME statement.
- DROP: Excludes variables from the output data set.
- RENAME: Rename variables in the output data set.
- KEEP: Retain specific variables in the output data set.

The INPUT Statement
The INPUT statement provides SAS overall guides for importing data into a new data set. It specifies the formatting of raw data values, which column values correspond to variables, and the name of the output variables. Here's the basic syntax of the statement:
INPUT Variable1 [$] [Column-position1 - Column-position2] [Informat.] ... ;
- Variable1: Name of the first variable in the output data set. You can append variables to the statement as many times as you need.
- Dollar Sign: If you want the Variable1 to be entered as a character variable, you should indicate it by adding a $.
- Column-position1 - Column-position2 (Optional): These optional indices define the first and last column positions in the raw data.
- Informat. (Optional): This specifies how the raw data is formatted (e.g., $240,000 or Mar 19, 2024).
List Input to Read Data
In a raw data file, when the values are separated by one or more spaces and there is no rule about their column positioning, we say the file is in a free format. To create a new SAS data set with a freely formatted data source, you can simply list the desired variable names in the INPUT statement. Variable names must be:
- Starting with an alphabet (A-Z, a-z) or an underscore (_) only.
- Not exceeding 32 characters.
- Having numbers other than the 1st position.
For example, let's consider the following data file:

Now, let's import this file using the following INPUT statement. This kind of INPUT statement is referred to as list input:
DATA StudentGrades;INFILE '/home/u63368964/source/student-grades.dat';INPUT StudentID $ Name $ Math Science English;RUN;

In the output data set, we see that the Math is entirely missing. This happens due to the existence of spaces between the first and last name in each data line. The list input is the most straightforward approach, but it comes with some limitations:
- Strict Delimiter: All values must be strictly separated by at least one space. Or you must specify the delimiter by the DLM= option in the INFILE statement.
- Missing Value Representation: Any missing values must be represented as a single period.
- Character Variable Limitations: Character variable values must not contain any spaces, and their maximum length is 8 characters, unless specified otherwise using the LENGTH statement.
In this example DATA step, list input instructs SAS to interpret any space between the first and last name as a delimiter, resulting in two separate values being populated for each observation. Thus, the last names are mistakenly assigned to the Math, which is numeric. Since character values cannot be converted into numeric values, all Math entries are missing.
Reading Fixed Format Data
If all data values are neatly arranged in columns, you can read them by specifying column indicators. The column indicators specify the first and last column position for each variable entered in fixed format. For example:
DATA StudentGrades;INFILE '/home/u63368964/source/student-grades.dat';INPUT StudentID $ 1-4 Name $ 6-20 Math Science English;RUN;
In this DATA step, the INPUT statement explicitly specifies raw data column ranges for each variable assignment. For example, any values in the 1-4 columns of the raw data will be assigned to the StudentID. Similarly, any values in the 6-20 columns will be assigned to the Name. For the remaining variables, we use the list input.

Compared to the list input, column indicators take several advantages:
- Character variables can contain spaces and have values of up to 32,767 characters.
- It's possible to skip values for unnecessary variables.
- Since the positions of columns to read are specified, they can be read in any order, and the same column can be read repeatedly.
For example, let's consider the following DATA step:
DATA StudentGrades2;INFILE '/home/u63368964/source/student-grades.dat';INPUT Name $ 6-20 Math Science StudentID $ 1-4 MathScore 21-22;RUN;
This DATA step creates Name, reading values in 6-20 column. Then it moves to the next values to populate Math, separated by a space. Similarly, it reads the next separated values to populate Science. These two variables are created by list input. After that, SAS reads values in 1-4 columns and populates StudentID. Lastly, it reads 21-22 column values again for another variable MathScore:

Pointer Controls in the INPUT Statement
By default, particularly when reading raw data without column indicators, the INPUT statement extracts data sequentially from the source, one value after another. However, this might not be ideal if your data isn't arranged in a straightforward way. This is where pointer controls come into play. They keep track of the current location for each data record and relocates as needed. Here are some common types of pointer controls:
- Column Pointer Controls:
- These allow you to move the pointer to a specific column position in the current data line.
- @n moves the cursor to n-th column.
- Sometimes you don't know the column number, but you do know that it always comes after a particular character string. In such situations, you can use the @'character string'.
- +n moves the cursor to the n-th column after the current position.
- Line Pointer Controls:
- These controls are used to move the pointer to another line in the data record.
- / moves the cursor to the next line.
- #n moves the cursor to the n-th line.
For example, data file in the figure shown below contains information about temperatures for the month of July for Alaska, Florida, and North Carolina. Each line contains the city, state, normal high, normal low, record high, and the record low temperature in degrees Fahrenheit.

Now, let's consider the following DATA step:
DATA JulyTemperatures;INFILE '/home/u63368964/source/temperatures.dat';INPUT @'State:' State $@1 City $@'State:' +3AvgHigh 2. AvgLow 2.RecordHigh RecordLow;RUN;
In the DATA step, @'State:' relocates current column position wherever right after the specified string, 'State:', in the raw data file, and populates State. Then, @1 moves the current position to the first column and read values for City. Similarly, @'State:' +3 locates the cursor to 3 columns after 'State:' string.

Let's consider another example. This time, each observation spans three lines of the data file: the first line contains first and last name, second line contains age, and the third line contains height and weights.

Now, let's consider the following DATA step:
DATA HeightWeights;INFILE '/home/u63368964/source/height-weight.dat';INPUT FirstName $ LastName $/ Age#3 Height Weight;RUN;
In this DATA step, / moves cursor to the next line after reading two variables. Similarly, #3 relocates the cursor to the third line of the raw data file:

Reading Data based on Conditions
The at sign (@) located at the end of the INPUT statement without any column indicator holds the cursor and executes the next SAS statement. Combining this with an IF-THEN statement, you can have different INPUT statements based on the conditional evaluations. For example:
DATA MyData;INPUT Year 1-4 @;IF Year=1988 THEN INPUT Day 5-7 Amount 8-10;IF Year=1989 THEN INPUT Day 6-8 Amount 10-12;DATALINES;19883.214919885.76141989 7.9 7641989 6.8 875;RUN;
In this DATA step example, after reading a value for Year, @ holds the cursor and proceed to the subsequent SAS statements. If the condition in the IF clause is evaluated by true, then it takes an action specified in the THEN clause.

Character and Date Informats
Sometimes, raw data values adhere to specific formatting conventions. For example, "1,000,001" is intended to be interpreted as a numeric value. However, the inclusion of commas within the value can pose some challenges when importing the value into a SAS dataset.
In the INPUT statement, informats provide instructions to SAS on how to interpret raw data values. The informats has the following forms:
$informatw. /* Character */informatw.d /* Numeric */informatw. /* Date */
The $ signifies that it is a character informat, w represents the total width, and d indicates the number of decimal places (applicable only to numeric informats). For example, let's consider the following raw data file:

In the file, we have dates and sales amounts with specific formats. To read this raw data properly, the following DATA step specifies informats after variable names:
DATA Sales;INFILE '/home/u63368964/source/sales.dat';INPUTSalesID $4.Product $ 6-16SalesDate MMDDYY10.Amount COMMA8.2@37 ProductWeight 4.2;RUN;
Here, MMDDYY10. instructs SAS to read the 10 values, such as 01/05/2023, as the number of days between January 1, 1960 and January 5, 2024. This is referred to as a SAS date value. (As for why January 1, 1960? There's no official confirmation, but the common belief is that the SAS founders chose January 1, 1960, as an easy-to-remember reference point. It might have been around the approximate birth date of a popular computer system at that time, such as the IBM 370. Regardless of the reason, this fixed date simplifies the date calculations within SAS.)
The next eight values should be interpreted as a number. The informat COMMA8.2 tells SAS that the raw data values are formatted with commas and two decimal places. Note that the total width of 8 includes the two decimal places and commas. For example, 1,250.00 occupies a total of 8 column spaces, encompassing one comma, one period, and two decimals.
All things considered, the output data set would be as follows:

Here are some informats that are commonly used:
| Informat | Raw Data | INPUT Statement | Results |
|---|---|---|---|
| Character | |||
| $CHARw. Reads character data - does not trim leading or trailing blanks. | John Doe Jane Doe | INPUT Name $CHAR10.; | John Doe Jane Doe |
| $UPCASEw. Converts character data to uppercase. | John Doe | INPUT Name $UPCASE10.; | JOHN DOE |
| $w. Reads character data - trims leading blanks. | John Doe Jane Doe | INPUT Name $10.; | John Doe Jane Doe |
| Date, Time, and Datetime | |||
| ANYDATEw. Reads dates in various date forms | 1jan1961 01/01/61 | INPUT MyDate ANYDATE10.; | 366 366 |
| DATEw. Reads dates in form: ddmmmyy or ddmmmyyyy | 1jan1961 1 jan 61 | INPUT MyDate DATE10.; | 366 366 |
| DATETIMEw. Reads dates in form: ddmmmyy hh:mm:ss.ss | 1jan1960 10:30:15 1jan1961,10:30:15 | INPUT MyDT DATETIME18.; | 37815 31660215 |
| DDMMYYw. Reads dates in from: ddmmyy or ddmmyyyy | 01.01.61 02/01/61 | INPUT MyDate DDMMYY8.; | 366 367 |
| MMDDYYw. Reads dates in form: mmddyy or mmddyyyy | 01-01-61 01/01/61 | INPUT MyDate 8.; | 366 366 |
| TIMEw. Reads time in form hh:mm:ss.ss (or hh:mm) | 10:30 10:30:15 | INPUT MyTime TIME8.; | 37800 37815 |
| Numeric | |||
| COMMAw.d Removes embedded commas and $, converts left parentheses to minus sign | $1,000,000.99 (1,234.99) | INPUT Income COMMA13.2; | 1000000.99 -1234.99 |
| COMMAXw.d Like COMMAw.d but switches role of comma and period | $1.000.000,99 (1.234,99) | INPUT Income COMMAX13.2; | 1000000.99 -1234.99 |
| PERCENTw. Converts percentages to numbers | 5% (20%) | INPUT MyNum PERCENT5.; | 0.05 -0.2 |
| w.d Reads standard numeric data | 1234 -12.3 | INPUT MyNum 5.1; | 123.4 -12.3 |
Informat Modifiers
Occasionally, you might be unsure about the exact width of the values. In such cases, you would provide a width that is reasonably long enough. However, this approach could result in output variables with some unwanted trailing values. For example, let's consider the following data file:

Suppose that you're not sure how long the width of the car model and color variable should be. However, executing the following DATA step would not work as intended:
DATA CarSales;INFILE '/home/u63368964/source/car-sales.dat';INPUT Month Day Year Model $15. Color $15. NumSales Price;RUN;

The colon modifier directs SAS to read the values up to the specified width, but stops at the first space (or other delimiter) it encounters. This ensures that the trailing values are not included in the variable. To use a colon modifier, simply put a colon (:), right in front of the informat specification.
DATA CarSales;INFILE '/home/u63368964/source/car-sales.dat';INPUT Month Day Year Model :$15. Color :$15. NumSales Price;RUN;

Let's consider another example. Suppose that you want to import this raw data file with four variables: Breeds, AvgHeight, AvgWeight, Temper. In the file, observations can potentially include a space.

Now, let's say that you're not sure about how long the Breed going to be. So, you cannot use column indicator. In such cases, to import this data file, you should use ampersand modifier &. It directs SAS to recognize a single space as part of a character variable, and two or more consecutive space characters are recognized as delimiters. For example.
DATA DogBreeds;INFILE '/home/u63368964/source/dog-breeds.dat';INPUT Breed &$50. AvgHeight AvgWeight Temper $;RUN;

Lastly, tilde modifier ~ instructs SAS to recognize double quotation marks ("") as a part of variable. It is typically used along with a DSD option, which make sure that SAS ignores any delimiter inside the double quotation marks. For example:

In the data file shown above, all values are delimited by commas. At the same time, the first variable also contains a comma in the double quotation mark. To import this file:
DATA HeightWeights2;INFILE '/home/u63368964/source/height-weight-v2.txt' DLM=',' DSD;INPUT Name :$15. Age Sex $ Weight Height;RUN;

Informat
Crafting new variables from raw data is often essential. In many cases, this practice can significantly improve the performance of statistical models and machine learning algorithms. Depending on the data type and analysis purpose, various techniques can be employed to derive new variables. When working with tabular data, commonly employed techniques include:
- Transformations: Combining multiple variables through mathematical operations performed on existing variables (e.g., calculating body mass index using height and weight.)
- Binning: Grouping continuous variables into categories (e.g., creating age ranges from a continuous age values.)
- Encoding: Converting categorical variables into numerical representations (e.g., one-hot encoding for colors.)
- Standardizing: Scaling variables to a common range, often between 0 and 1 or with a mean of 0 and standard deviation of 1.
In a SAS DATA step, you can easily define a new variable as follows:
NewVariable = Expression;
On the left side of the equal sign is the variable name, which can be either a new one, to append one more variable to the data set, or existing one, to re-define it by the expression. On the right side of the equal sign can be a constant, an existing variable, or mathematical expressions combining them. Here are available mathematical expressions:
| Operation | Description | Example |
|---|---|---|
| Numeric constant | Assigns the value 10 to the variable x. | x = 10; |
| Character constant | Assigns the string "John" to the character variable name. | name = "John"; |
| New variable | Assigns the sum of num1 and num2 to the new variable total. | total = num1 + num2; |
| Addition | Adds the values of num1 and num2 and assigns the result to the variable total | total = num1 + num2; |
| Subtraction | Subtracts the value of num2 from num1 and assigns the result to the variable difference. | difference = num1 - num2; |
| Multiplication | Multiplies the values of num1 and num2 and assigns the result to the variable product. | product = num1 * num2; |
| Division | Divides the value of num1 by num2 and assigns the result to the variable quotient. | quotient = num1 / num2; |
| Exponentiation | Raises the value of base to the power of exponent and assigns the result to the variable result. | result = base ** exponent; |
SAS follows the standard mathematical rules of precedence: exponentiation takes precedence, followed by multiplication and division, lastly addition and subtraction. Parentheses can be used to override this order.
Let's consider an example scenario. According to fitness experts, the one-repetition maximum (one-rep max or 1RM) in weight training refers to the maximum weight an individual can possibly lift for a single repetition. Based on the past workout logs, there are several different ways to calculate 1RM:

The following DATA steps perform different 1RM calculations using Reps and Weights:
DATA WorkoutLogs;INPUT Timestamp :DATETIME. Excercise $ Reps Sets Weights;DATALINES;27MAR2023:08:00:00 Squats 10 3 10027MAR2023:08:15:00 Push-ups 15 3 027MAR2023:08:30:00 Bench-press 8 4 12027MAR2023:08:45:00 Deadlifts 12 3 15027MAR2023:09:00:00 Lunges 10 3 8027MAR2023:09:15:00 Pull-ups 8 4 027MAR2023:09:30:00 Bicep-curls 12 3 4027MAR2023:09:45:00 Planks . . .27MAR2023:10:00:00 Shoulder-press 10 3 50;RUN;DATA OneRepMax;SET WorkoutLogs;Epley = Weights * (1 + 0.0333 * Reps);Brzycki = Weights / (1.0278 - 0.0278 * Reps);Lombardi = Weights * Reps ** 0.1;OConner = Weights * (1 + 0.025 * Reps);Wathan = Weights * 100 / (48.8 + 53.8 * EXP(-0.075 * Reps));RUN;

In addition to the arithmetic operations, SAS provides some built-in mathematical functions:
| Function | Description | Example |
|---|---|---|
| ROUND(x, int) | Rounds a numeric value to a specific number of decimals. | ROUND(3.141592, 2) returns 3.14. |
| INT(x) | Returns the integer part of x, by truncating any fractional digits. | INT(3.75) returns 3 INT(-2.1) returns -2. |
| ABS(x) | Returns the absolute value of x. | ABS(-5) returns 5. |
| CEIL(x) | Returns the smallest integer that is greater than or equal to x. | CEIL(4.3) returns 5 CEIL(-1.5) returns -1. |
| FLOOR(x) | Returns the largest integer that is less than or equal to x. | FLOOR(4.8) returns 4 FLOOR(-1.5) returns -2. |
| LOG(x) | Returns the natural logarithm of x (base-e logarithm). | LOG(10) returns 2.302585. |
| EXP(x) | Returns the base-e raised to the power of x. | EXP(1) returns 2.71828. |
| SQRT(x) | Returns the square root of x. | SQRT(9) returns 3. |
| MAX(arg1, arg2, ...) | Returns the maximum value among the arguments. | MAX(5, 10, 3) returns 10. |
| MIN(arg1, arg2, ...) | Returns the minimum value among the arguments. | MIN(5, 10, 3) returns 3. |
| SUM(arg1, arg2, ...) | Calculates the sum of the arguments (arg1, arg2, ...) | SUM(5, 10, 3) returns 18. |
| MEAN(arg1, arg2, ...) | Calculates the sum of the arguments (arg1, arg2, ...) | MEAN(5, 10, 3) returns 6. |
It is worth noting that the functions listed above perform element-wise calculations across variables within an observation, not across observations within a variable. For example:
DATA OneRepMax;SET WorkoutLogs;Epley = Weights * (1 + 0.0333 * Reps);Brzycki = Weights / (1.0278 - 0.0278 * Reps);Lombardi = Weights * Reps ** 0.1;OConner = Weights * (1 + 0.025 * Reps);Wathan = Weights * 100 / (48.8 + 53.8 * EXP(-0.075 * Reps));MaxRM = MAX(Epley, Brzycki, Lombardi, OConner, Wathan);MinRM = MIN(Epley, Brzycki, Lombardi, OConner, Wathan);RUN;PROC PRINT DATA=OneRepMax;RUN;

Let's consider another example. In the following raw data file, Month, Day, and Year variables are delimited by spaces.

When importing this file into a SAS data set, we want to craft a variable of SAS date values, combining these three pieces of information. You can achieve this through the MDY(month, date, year) function as follows:
DATA CarSales;INFILE '/home/u63368964/source/car-sales.dat';INPUT SalesMonth SalesDate SalesYear Model $ Color $ Quantity Price;SasDate = MDY(SalesMonth, SalesDate, SalesYear);RUN;PROC PRINT DATA=CarSales;RUN;

Using IF-THEN Statements to Craft New Variables
Instead of applying an expression to all observations, we often want to use it only for those that meet certain criteria. This is called conditional logic, and you do it with IF-THEN statement in SAS programming.
IF condition THEN action;
If condition evaluated to be true, then SAS executes action. Here are operators that can be used in the condition part:
| Symbolic | Mnemonic | Description |
|---|---|---|
| = | EQ | Checks if two values are equal. |
| ~= | NE | Checks if two values are not equal. |
| ^= | NE | Checks if two values are not equal. |
| > | GT | Checks if the left operand is greater than the right operand. |
| >= | GE | Checks if the left operand is greater than or equal to the right operand. |
| < | LT | Checks if the left operand is less than the right operand. |
| <= | LE | Checks if the left operand is less than or equal to the right operand. |
| & | AND | All comparisons must be true. |
| | | OR | Only one comparison must be true. |
For example, in the CarSales data set, let's say that we also want to mark SalesQuarter based on SalesMonth variable. In a DATA step, you can do this by applying YYQ(year, quarter) function in IF-THEN statements:
DATA CarSales;INFILE '/home/u63368964/source/car-sales.dat';INPUT SalesMonth SalesDate SalesYear Model $ Color $ Quantity Price;IF SalesMonth LE 3 THEN SalesQuarter = YYQ(SalesYear, 1);IF SalesMonth GT 3 AND SalesMonth LE 6 THEN SalesQuarter = YYQ(SalesYear, 2);IF SalesMonth GT 6 AND SalesMonth LE 9 THEN SalesQuarter = YYQ(SalesYear, 3);IF SalesMonth GT 9 THEN SalesQuarter = YYQ(SalesYear, 4);RUN;PROC PRINT DATA=CarSales;RUN;
Note that the created SAS date will be the first day of the quarter.

The IN operator checks if there is any matches in the list of values. For example, within an observation, if Model matches any of the list values ('Sedan', 'SUV', 'Hatchback'), then assigns 'Passenger' to CarType:
DATA CarSales;LENGTH Model $10. CarType $10.;INFILE '/home/u63368964/source/car-sales.dat';INPUT SalesMonth SalesDate SalesYear Model $ Color $ Quantity Price;IF Model IN ('Sedan', 'SUV', 'Hatchback') THEN CarType = 'Passenger';ELSE CarType = 'Commercial';RUN;PROC PRINT DATA=CarSales;RUN;

Note that a single IF-THEN statement can only have one action. However, by incorporating DO-END block, you can execute more than one action. For example:
DATA CarSales;LENGTH Model $10. CarType $10.;INFILE '/home/u63368964/source/car-sales.dat';INPUT SalesMonth SalesDate SalesYear Model $ Color $ Quantity Price;IF Model NOT IN ('Sedan', 'SUV', 'Hatchback') THEN DO;CarType = 'Commercial';SalesTax = Price * 0.06;ELSE DO;CarType = 'Passenger';SalesTax = Price * 0.1;RUN;PROC PRINT DATA=CarSales;RUN;

Subsetting IFs
Sometimes, it may be necessary to remove observations from a data set based on certain conditions. In such situations, you can use the DELETE statement along with the IF-THEN/ELSE statements. For example:
DATA PassengerVehicleSales;INFILE '/home/u63368964/source/car-sales.dat';INPUT SalesMonth SalesDate SalesYear Model $ Color $ Quantity Price;IF Model = 'Truck' THEN DELETE;RUN;PROC PRINT DATA=PassengerVehicleSales;RUN;

Working with SAS Dates
In SAS, a variable can hold either character or numeric values. Any date values are represented as the number of days since January 1, 1960. However, this representation can be confusing, particularly when performing calculations involving time intervals like months or years. For example, the varying number of days in different months complicates tasks such as adding or subtracting a month from a date value. Similarly, determining the number of intervals between two dates is also challenging. To address these issues, you can employee the following functions:
- INTNX('interval', from, n): This function adds n-intervals to the dates specified at from argument.
- INTCK('interval', from, to): This function calculates how many intervals between from and to dates.
For example, let's consider the following DATA step:
DATA Employees;INFILE '/home/u63368964/source/employees.csv' FIRSTOBS=2 DLM=',' TRUNCOVER;/* Specifying date value representations */ FORMAT Dob DATE10. StartDate DATE10. EndDate DATE10. TenYearsAnniversary WORDDATE18.; INPUT EmployeeID $4. GivenName :$15. SurName :$15. Dob DDMMYY10. JobTitle :$25. StartDate :DATE10. EndDate ?:DATE10.; Age = INTCK('Year', Dob, TODAY()); IF EndDate = '.' THEN DO; YearsInOffice = INTCK('Year', StartDate, TODAY()); TenYearsAnniversary = INTNX('Year', StartDate, 10); NumDaysToAnniversary = INTCK('Day', StartDate, TenYearsAnniversary); END; ELSE TenureMonths = INTCK('Month', StartDate, EndDate); DROP EmployeeID JobTitle; RUN; PROC PRINT DATA=Employees; RUN;
In the DATA steps above, the INTCK() functions are employed to calculate number of years and days between the two SAS date variables. Here, TODAY() function retrieves the current date from the system. For example, Age = INTCK('Year', Dob, TODAY()); counts the number of years between the date values stored in Dob and system date. On the other hand, the INTNX() function is used to calculate the SAS date that is 10 years after the StartDate variable.

By default, the first year of a hundred-year span is set to be 1960. However, you can change this setting with the YEARCUTOFF= option. The YEARCUTOFF= option is helpful when the raw date values are stored with two-digits. For example, if a date value is provided by 07/04/76, it is ambiguous whether it means 1976, 2076, or possibly 1776, and so on. To avoid this issue:
OPTIONS YEARCUTOFF = 1950;
This statement ensures that the two-digit dates are between 1950 and 2049, and thereby 07/04/76 represents July 4th, 1976.
Manipulating Character Variables
In SAS, characters refer to any alphanumeric values enclosed by a pair of quotation marks. They represent categorical or factor variables in SAS data sets.
When processing these character variables, the standard arithmetic operators and functions typically cannot be applied directly. Even if an operator can be applied to the variables, the results could be tricky.
Concatenation Operator
One of the most common operator to manipulate character variables is the concatenation operator (||). This operator concatenates two character variables on its left and right-hand sides into a single variable. For example, let's consider the following DATA step:
DATA Employees;INFILE '/home/u63368964/source/employees.csv' FIRSTOBS=2 DLM=',' TRUNCOVER;INPUT EmployeeID $4. GivenName :$15. SurName :$15. Dob DDMMYY10. JobTitle :$25. StartDate :DATE10. TerminationDate ?:DATE10.; EmployeeName = TRIM(SurName) || ', ' || GivenName; KEEP SurName GivenName EmployeeName; RUN;
In the code lines above, concatenation operators combine SurName, ',', and GivenName. Here, to remove any trailing blank spaces in SurName, the TRIM function is applied.

Applying Comparison Operators on Character Variables
The comparison operators, such as > (GT), = (EQ), or ^= (NE), is not limited to numeric values; they can also be applied to compare two character variables. When comparing two character variables, the evaluation is based on either ASCII or EBCDIC collating sequence order. While IBM mainframes employ EBCDIC, most PCs, including SAS Studio environments, use ASCII, where blank spaces come first, followed by numbers, uppercase letters, lowercase letters, and non-Latin alphabets. For example:
DATA Employees;INFILE '/home/u63368964/source/employees.csv' FIRSTOBS=2 DLM=',' TRUNCOVER;INPUT EmployeeID $4. GivenName :$15. SurName :$15. Dob DDMMYY10. JobTitle :$25. StartDate :DATE10. TerminationDate ?:DATE10.; EmployeeName = TRIM(SurName) || ', ' || GivenName;IF JobTitle >= 'Area Sales Manager' THEN DELETE; KEEP EmployeeName JobTitle; RUN;
This DATA step subsets raw data by comparing character strings. In the raw data file, there are 3,000 rows in total. However, after subsetting, the returning output contains only 66 observations.

Selected Functions for Character Variables
In addition to the two operators mentioned earlier, SAS also provides some built-in functions for character manipulations:
| Function Name | Description | Example | Result |
|---|---|---|---|
| ANYALNUM(arg, start) | Returns position of first occurrence of any alphabetic character or numeral at or after optional start position. | a='123 E St, #2 '; x=ANYALNUM(a); y=ANYALNUM(a,10); | x=1 y=12 |
| ANYALPHA(arg, start) | Returns position of first occurrence of any alphabetic character at or after optional start position. | a='123 E St, #2 '; x=ANYALPHA(a); y=ANYALPHA(a,10) | x=5 y=0 |
| ANYDIGIT(arg, start) | Returns position of first occurrence of any numeral at or after optional start position. | a='123 E St, #2 '; x=ANYDIGIT(a); y=ANYDIGIT(a,10) | x=1 y=12 |
| ANYSPACE(arg, start) | Returns position of first occurrence of a white space character at or after optional start position. | a='123 E St, #2 '; x=ANYSPACE(a); y=ANYSPACE(a,10) | x=4 y=10 |
| CAT(arg-1, arg-2, ... arg-n) | Concatenates two or more character strings together leaving leading and trailing blanks. | a=' cat'; b='dog '; x=CAT(a,b); y=CAT(b,a); | x=' catdog ' y='dog cat' |
| CATS(arg-1, arg-2, ... arg-n) | Concatenates two or more character strings together stripping leading and trailing blanks. | a=' cat'; b='dog '; x=CATS(a,b); y=CATS(b,a); | x='catdog' y='dogcat' |
| CATX('separator-string', arg-1, arg-2, ... arg-n) | Concatenates two or more character strings together stripping leading and trailing blanks and inserting a separator string between arguments. | a=' cat'; b='dog '; x=CATX('&',a,b); | x='cat&dog' |
| COMPRESS(arg, 'char') | Removes spaces or optional characters from argument. | a=' cat & dog '; x=COMPRESS(a); y=COMPRESS(a,'&'); | x='cat&dog' y=' cat dog ' |
| INDEX(arg, 'string') | Returns starting position for string of characters. | a='123 E St, #2 '; x=INDEX(a,'#') | x=11 |
| LEFT(arg) | Left aligns a SAS character expression. | a=' cat'; x=LEFT(a); | x='cat ' |
| LENGTH(arg) | Returns the length of an argument not counting trailing blanks (missing values have a length of 1). | a='my cat'; b=' my cat '; x=LENGTH(a); x=LENGTH(b); | x=6 y=7 |
| PROPCASE(arg) | Converts first character in word to uppercase and remaining characters to lowercase. | a='MyCat'; b='TIGER'; x=PROPCASE(a); y=PROPCASE(b); | x='Mycat' y='Tiger' |
| SUBSTR(arg, position, n) | Extracts a substring from an argument starting at position for n characters or until end if no n. | a='(916)734-6281'; x=SUBSTR(a,2,3); | x='916' |
| TRANSLATE(source, to-1, from-1, ... to-n, from-n) | Replaces from characters in source with to characters (one to one replacement only - you can't replace one character with two, for example). | a='6/16/99'; x=TRANSLATE (a,'-','/'); | x=6-16/99 |
| TRANWRD(source, from, to) | Replaces from character string in source with to character string. | a='Main Street'; x=TRANWRD (a,'Street','St.'); | x='Main St.' |
| TRIM(arg) | Removes trailing blanks from character expression. | a='My '; b='Cat'; x=TRIM(a)||b; | x='MyCat' |
| UPCASE(arg) | Converts all letters in argument to uppercase. | a='MyCat'; x=UPCASE(a) | x='MYCAT' |
PDV Automatic Variables
During the process of populating PDV, SAS automatically generates temporary variables to store some information. These variables are known as automatic variables. Below is the list of these variables:
- _N_: This variable is an integer that holds the current observation number within the DATA step. It starts at 1 and increments by 1 for each observation processed.
- _ERROR_: This is a numeric variable that indicates whether an error occurred during the current observation processing. A value of 1 signifies an error has been encountered, while 0 indicates no error.
- FIRST.BY and LAST.BY: These two automatic variables are created for each BY variable you specify in the BY statement. They are Boolean (1 or 0) and indicate the position within a BY group:
- 1: The variable is set to 1 for the first observation in a BY group.
- 0: The variable is set to 0 for subsequent observations within the same BY group.
- 1 again: It changes back to 1 when a new BY group starts.
For example:
DATA One;INPUT VarA;DATALINES;123;DATA Two;INPUT VarB;DATALINES;11121314;DATA Three;INPUT VarC;DATALINES;3132333435;DATA Combine;SET One;IF _N_ = 2 THEN SET Two;IF _N_ = 3 THEN SET Three;RUN;
In this example, _N_ is initialized to 1 during the first iteration. Then, SAS processes the second statement SET One;, which reads the first observation from the data set One. Since _N_ = 1 for the current iteration, the remaining SET statements will not be executed.
Next, _N_ is incremented by 1, so now _N_ = 2. This time, after executing SET One;, SAS also executes SET Two, as _N_ = 2 evaluates to true. Here, it is important to note that _N_ values are based on the data source. Thus, for the current observation, VarA would be the second observation from the data set One. On the other hand, SET Two reads the first observation from the data set Two, concatenating it horizontally.
Then, _N_ is incremented again by 1, so not _N_ = 3. So, it reads the third observation from the data set One. This time, since _N_ = 3, SET Two is not executed; instead, SET Three is executed and reads the first observation from the data set Three. However, VarB of the third observation will be 11, not missing. This is because PDV for the current observation is created by copying that of the previous observation. So, in this example, SAS copies the second observation and then executes the three statements in the DATA step, starting from SET One;.

Generally, automatic variables exist temporarily only while reading objects and are not stored in the output data set. So, if you want to see the variables in your output, you should explicitly specify it as follows:
DATA Combine2;SET One;IF _N_ = 2 THEN SET Two;IF _N_ = 3 THEN SET Three;Nobs = _N_;Error = _ERROR_;RUN;

In tasks like report writing and data management, a common requirement is to identify the beginning and end of each group of observations. Two automatic variables, FIRST.BY and LAST.BY, store the start and end of observation groups defined by the BY variables.
One useful applications of FIRST.BY and LAST.BY is checking whether the two consecutive observations for a variable are different. For example:
DATA One;INPUT VarA VarB;DATALINES;A 1B 2D 3C 5C 4C 6D 7;DATA Two;SET One;BY VarA NOTSORTED;First = FIRST.VarA;Last = LAST.VarA;RUN;
In this example, the data set Two maintains the same order as One. The NOTSORTED option allows you to use the BY statement without sorting it first. Thus, in this example, the automatic variable FIRST.VarA acts as a marker, checking if the VarA value in the current observation is different from its preceding one. Similarly, LAST.VarA also acts as a marker, checking if VarA in the next observation is different from the current one.

RETAIN Statement
At the moment it is created for the first variable, the PDV is an empty vector. Then, SAS reads data from the specified data source, and populates PDV by the instructions. In the process, the RETAIN statement provides a specific value for this initial state of variable and preserves it to the next iteration. The RETAIN statement can appear anywhere in the DATA step and has the following form:
RETAIN Variable-1 [Initial-value-1] ... ;
Where:
- Variable-1: Name of the variable where you want to retain the initial value.
- Initial-value-1 (Optional): The initial value of the variables specified in the statement. If omitted, it defaults to a missing value.
You can have as many variable-value pairs as needed. For example, let's consider the following data file:

This data file logs the active energy consumption in Watt-hours by a household on a per-minutes basis, calculated as Global_active_power * 1000 / 60 - Sub_metering_1 - Sub_metering_2 - Sub_metering_3. Now, let's consider the following DATA step:
DATA EnergyConsumption;INFILE '/home/u63368964/source/household-power-consumption.txt' DLM=';' FIRSTOBS=2;INPUT Date :ANYDTDTE10. Time TIME8. GlobalActivePower GlobalReactivePower Voltage GlobalIntensity SubMetering1 SubMetering2 SubMetering3; /* Calculate active energy consumption */ ActiveEnergyConsumption = GlobalActivePower * 1000 / 60 - SUM(SubMetering1, SubMetering2, SubMetering3); /* Keep record high of the active energy consumption */ RETAIN RecordHigh; RecordHigh = MAX(RecordHigh, ActiveEnergyConsumption); RUN;
In the DATA step, RETAIN RecordHigh; declares a variable with its default missing value. Subsequently, RecordHigh = MAX(RecordHigh, ActiveEnergyConsumption); updates the RecordHigh variable to store the maximum value encountered thus far, comparing the ActiveEnergyConsumption in the current PDV with the previously stored value in the variable. The updated RecordHigh value will be preserved until it encounters larger value in the iterations.

Calculating Running Totals
One of the most common places where you can leverage the RETAIN statement would be calculating running totals. A running total is the cumulative sum of a sequence of numbers. It gets updated each time a new number is added to the sequence by adding the value of the new number to the previous running total. For example, let's consider the following DATA step:
DATA EnergyConsumption2;SET EnergyConsumption;RETAIN RunningTotal -10;RunningTotal = SUM(RunningTotal, ActiveEnergyConsumption); RUN;
This DATA step builds upon the previous one and calculates a running total for the ActiveEnergyConsumption. To be more specific, RETAIN RunningTotal -10; declares a variable named RunningTotal that's retained across observations within the DATA step. It is initialized to -10, representing the starting point for the running total.
Subsequently, RunningTotal = SUM(RunningTotal, ActiveEnergyConsumption); calculates and updates the RunningTotal for each observation. It uses the SUM function to combine the RunningTotal from the previous iteration with the current ActiveEnergyConsumption.

An alternative way to achieve the same result is the sum statement; it doesn't require any keyword or equal sign, and retains values from the previous iteration of the DATA step. Essentially, this statement cumulatively adds the values of an expression to a variable.
variable + expression;
For example:
DATA EnergyConsumption3;SET EnergyConsumption;RunningTotal + ActiveEnergyConsumption;RUN;

Carry-over Calculations
For basic calculations that require a value from the previous observation, RETAIN can be a quick solution. Let's consider the following DATA step:
DATA EnergyConsumption4;SET EnergyConsumption;RETAIN PreviousConsumption;CurrentDifference = ActiveEnergyConsumption - PreviousConsumption;PreviousConsumption = ActiveEnergyConsumption;RUN;
In this DATA step, the PreviousConsumption is initiated with a missing value for the first observation. Then the CurrentDifference is calculated subtracting this from the current ActiveEnergyConsumption. After that, PreviousConsumption is updated by the current ActiveEnergyConsumption, so that the two variables have the same value before moving onto the next observation.
.


{kind=link}
0 Comments